基于自监督学习的图转移网络会话推荐算法①
潘 茂 张梦菲 辛增卫 金佳琪 郭 诚 方金云
(*中国科学院计算技术研究所 北京100190)
(**中国科学院大学 北京100190)
(***国家计算机网络应急技术处理协调中心 北京100029)
推荐系统作为解决信息过载的有效方法,是学术界[1-2]和工业界[3-6]的研究热点之一。基于会话的推荐算法(session-based recommendation,SBR)是推荐系统领域一个重要的研究分支。不同于传统的推荐算法,SBR 的用户通常是匿名的,即没有历史交互信息,只有当前会话序列信息。SBR 旨在根据当前会话序列,及时准确地捕捉匿名用户短期、动态的兴趣以推荐用户感兴趣的物品。
根据建模方式不同,当前SBR 研究主要分为如下3 类:(1)基于矩阵分解[7-8]的方法;(2)基于循环神经网络[9-10](recurrent neural networks,RNN)的方法;(3) 基于图神经网络[11-13](graph neural networks,GNN)的方法。上述方法的共性是:独立建模当前用户的会话信息,通过学习同一会话内的用户序列点击行为,得到每个物品和会话的向量表达,最终完成推荐。然而,这类基于当前会话子序列的SBR 算法,仅仅建模当前会话内的物品关系,建模信息过于单一,存在一定程度的数据稀疏性问题,导致模型拟合性不佳,存在预测偏差。
本文认为不同会话间物品的协同信息可以增强当前会话的物品表示学习,缓解数据稀疏性问题。例如,2 个用户的不同会话:iPhone XR→Airpods→Mi 11 和iPhone 11→Mi 11→iPhone 12→Airpods,预测用户在第1 个会话中点击了Mi 11 之后感兴趣的物品,可以融合存在相似行为模式的第2 个会话的协同信息来辅助学习。
为解决以往SBR 算法中的稀疏性问题,本文提出一种基于自监督学习的图转移网络协同会话推荐算法(self-supervised graph transition network for session-based recommendation,S-SGTN)。该算法首先基于当前会话序列和所有会话序列构造局部会话图和协同会话图,用于描述会话中物品的局部和协同信息。其中协同会话图是由与目标物品相似的物品节点构成,局部会话图由当前会话中的物品组成。其次,利用双通道图转移网络(graph transition network,GTN)捕捉当前会话内和不同会话间物品的转移关系,然后将自监督学习融入到网络训练中,把最大化局部和全局表示的互信息的任务作为推荐任务的辅助任务,进一步剔除与当前物品不相关的物品,以更好地抽取目标物品的潜在邻居的特征信息,弥补建模当前会话中物品信息的不足,进而改进物品和会话的表示。最后,计算候选集合中的物品表示与上一步得到的会话表示的相似度,进而实现对用户下一个交互物品的预测。综上所述,本文的主要贡献如下。
(1)提出一种双通道图转移网络,可以同时捕捉同一会话内物品的转移信息和不同会话间物品的协同信息。
(2)在网络训练中,创建自监督学习任务,作为推荐任务的辅助任务,能更好地聚合邻居节点特征,进而优化物品的表示,提升模型的推荐效果。
(3)在3 个公开数据集的实验结果中,本文提出的S-SGTN 算法效果优于其他基线算法。
本节详细阐述了与本文相关的研究工作,包括传统的方法、深度学习的方法以及自监督学习的方法。
1.1 传统的会话推荐算法
一般来说,传统的SBR 都是基于启发式的思想,本质上是通过建模物品或者会话之间的相似度来为用户提供推荐服务。基于K 最近邻(k nearest neighbor,KNN)的算法[1],首先寻找和目标物品或会话相近的物品和会话,然后通过计算候选集物品与当前会话的相似度来推荐。基于分解个性化马尔可夫链的模型[7](factorizing personalizing Markov chains,FPMC),结合传统的矩阵分解(matrix factorization,MF)和马尔可夫链模型(Markov chains,MC),通过分解底层的转移矩阵来建模用户的序列行为。但该模型假设序列中仅相邻物品是有关系的,故无法捕捉序列的全局信息。
这些传统的SBR 算法在物品间依赖关系比较简单的数据集上效果可以和基于深度学习的SBR算法相媲美,但是其忽略了用户的动态行为,无法建模会话内和会话间物品之间复杂的高阶依赖关系。
1.2 基于深度学习的会话推荐算法
随着深度学习的飞速发展,基于深度学习的方法也广泛应用到SBR 领域[11]。Hidasi 等人[9]提出GRU4Rec 模型,该算法将RNN 应用到SBR 领域。在GRU4Rec 的研究基础上,Quadrana 等人[10]提出层次化RNN 模型,分别刻画会话和用户信息。在建模会话意图方面[14-16],Guo 等人[16]提出一种跳跃网络来建模用户的兴趣变化。Wu 等人[11]将用户的会话信息建模成图结构数据,并用门控图神经网络(gated graph neural network,GGNN)捕捉会话中物品之间的高阶转移关系,并取得相比以往RNN 模型更好的推荐效果。
1.3 基于自监督学习的推荐算法
推荐系统中的自监督学习方法[13,17]通过构造不同视图的表征,利用自监督信号来增强网络的表达能力。Xia 等人[13]提出自监督的超图网络捕捉会话中物品间的超配对关系,并通过融合超配对关系的会话表示完成相应的推荐。在序列推荐方面,Zhou 等人[17]提出基于自注意力机制的模型框架并利用数据的内在关联性来构建自监督函数,然后通过训练的方式来增强数据的表示,以改进序列推荐的效果。
S-SGTN 模型架构如图1 所示,从左到右分别是会话序列层、会话图层、图转移网络层、自监督学习层、物品和会话的表示层、预测层。

图1 基于自监督学习的图转移网络会话推荐算法的整体框架图
会话序列层包含所有匿名用户的会话序列,下游会话图层中的会话图即由其构建而成。图转移网络层是由局部和协同会话图两部分组成的双通道图卷积神经网络(graph convolution network,GCN)构成,该网络不同于传统的GCN 网络,特征变换和非线性激活由更简单有效的均一化求和(normalized sum)操作代替[18]。网络的输入信息分别是目标物品在局部会话图中的表示和在协同会话图中的所有邻居节点的表示,经过多层GTN 聚合以后,图转移网络层的双通道分别输出融合了局部和协同全局信息的目标节点表示。在自监督学习层,上述双通道节点表示被作为物品在局部和全局2 个不同层面但可以互补的信息表现形式,互相作为彼此的监督信号,并把最大化它们之间互信息的任务作为推荐任务的辅助任务,以去除不相关的物品信息,更好地聚合目标物品邻居节点的特征信息,优化物品的表示。最后通过注意力机制学习会话的表示,计算并预测候选集合中物品的点击概率。
2.1 相关定义
定义1物品信息和对应的会话序列S的定义:物品字典V={v1,v2,…,v|V|},其中| V|表示无重复的物品总数,给定一个会话序列S={vs,1,vs,2,…,vs,n},vs,t∈V表示在会话S中匿名用户在t时刻产生交互行为的物品。
定义2物品的邻居物品节点的定义:对于物品vi∈S,其k跳(k-hop)的邻居物品节点集合= {vp | p∈[i -k,i+k]}。
定义3会话图:会话序列S构成一张图={VS,ES},其中每一个节点vs,i∈VS代表一个物品节点,图的每一条边(vs,t-1,vs,t) ∈ES表示用户的一次交互行为。
定义4协同会话图:根据定义2,对于∀vi∈V,可得到其邻居节点集合Nvi,然后构造协同会话图,其中分别表示协同会话图的节点和边。
根据上面对物品和会话信息的定义,SBR 算法是在已知会话序列S的条件下,输出会话向量表示S和每个候选物品vi的评分的数值表示用户可能与该物品交互的概率,用于预测下一个产生交互的物品vs,n+1。
2.2 会话图
会话图是由包含用户行为信息的物品序列构成。研究表明,在一定序列长度内,同一会话中的相邻物品具有较大的相似性或关联关系[2,6,11]。受此启发,为弥补单个会话图中物品信息的不足,本文组建协同会话图,以从全局层面上建模物品的表示。其中,协同会话图是由数据集中所有会话序列经过一定的处理方式构建而成。构建方式如下所述。
首先对数据集所包含的每一个物品构建倒排表,其中倒排表是由目标物品的邻居物品组成。如图2 所示,以物品节点v4为例,假设要构建的是目标物品v4的倒排表,根据上文的定义2,从数据集中所有会话序列,选取v4的2 跳邻居节点集合,即v4的倒排表为{v1,v2,v3,v5,v6,v7}。以此类推,依次构建物品v1,…,vn的倒排表。为了降低噪声节点的影响,本文对生成的倒排表进行了优化处理,仅选取倒排表中和目标物品共现频次较高的物品。本文选取的阈值为8,其中共现频次的计算是由数据集统计得到。所以目标物品v4的最终倒排表为{v1,v2,v5,v7}。最后将所有目标物品和其倒排表中的物品节点直接相连以组建全局的协同会话图。

图2 会话图的构建示意图
由以上会话图的组建过程可知,局部会话图是由单一会话中的物品节点构成,根据会话中的行为序列,直接建立的无向图;协同会话图是从相似物品的层面上出发,并对物品的倒排表进一步优化处理,降低不相关物品对会话图的影响。如果一个物品出现在不同的会话序列中,其邻居节点信息是不同的。
2.3 物品的嵌入表示
由于原始物品ID 的表达能力有限,并不能建模物品与物品之间的内在关联性。因此,本文先将物品ID 映射为独热(one-hot)编码(目标物品所在位置为1,其他数值为0),再将one-hot 编码通过投影矩阵H∈RN×d转化为低维稠密的向量表示:X=表示物品vi的嵌入向量(embedding),其中d是向量的维度。投影矩阵的参数将通过端到端训练的方式与模型其他层的参数一起学习。
2.4 物品的表示学习
根据当前会话S的局部会话图和协同会话图,分别在和图中选取目标节点vi的邻居节点集合和,然后将它们的embedding 输入到双通道GTN 中,学习vi在局部会话图和全局会话图中的表示。
由于一层GTN 网络仅能学习到一阶邻居节点之间的关联性,无法捕捉多阶邻居节点之间的复杂转移关系,故本文采用多层的网络结构来学习目标物品融合高阶邻居的信息表示。如图1 所示,GTN中的每一层均通过均一化求和函数做融合计算,并输入融合l阶信息的表示到下一层。均一化求和函数核心思想是通过聚合目标物品上一个状态的表示和其邻居物品的上一个状态的表示来生成目标物品下一个状态的表示,以此更新迭代物品的embedding表示。具体计算方式如下:
随着GTN 层数的增加,图中节点之间的表示逐渐平滑并接近,并且不同层的物品节点表示捕获的是不同的语义特征。因此,对序列中的物品表示加权求和相较于仅用最后一层的表示效果更佳,使得物品的表示更加全面[18-19]。所有物品节点经过L层GTN 网络特征聚合以后,生成物品的局部表示集合和全局表示集合:
最终通过聚合函数(aggregator)生成融合局部和全局协同信息的物品表示集合Ev:
其中evi是经过双通道GTN 学习到的vi的表示,计算方式如下:
本文采用加和操作来作为聚合函数,并在3.7 节给出不同聚合函数选择的对比实验分析。
由于相同物品在不同会话中的邻居节点不同,所以最终学习到的同一物品在不同会话中的表示也不同,具有动态性。
2.5 自监督学习
自监督学习作为深度学习的一种,其与监督学习不同之处是:自监督学习避免了对数据集进行大量的标签标注工作,通过自身定义的伪标签作为训练信号,从而将学习到的表示用于下游任务。即自监督学习可以对用户的显式数据进行增强,因此可以用来解决推荐系统中数据稀疏性问题,更好地聚合邻居节点特征,优化物品的表示。
对比学习作为自监督学习的一种判别式模型,其核心思想是:使得相似样本之间的距离变近,不同样本之间的距离变远[20]。
本文组建协同会话图可以弥补局部会话图中物品信息的不足问题,缓解数据稀疏性。因此,创建自监督学习的子任务,来辅助建模物品的表示,用于下游的会话表示学习。自监督学习可以分为自监督信号的创建(前置任务)和对比学习两部分。
前置任务是自监督学习中非常重要的一个策略,可以用伪标签从数据中学习表示。基于此,本文中的双通道GTN 是从协同会话图和局部会话图2个层面刻画同一个物品的表示。在训练过程中,物品在局部会话图中的表示和协同会话图中的表示作为彼此的真值(ground truth),且这种一对一的对应关系即是伪标签(标签的增广),即彼此的自监督信号。
对比学习总体上可以分为负样本的构建、数据样本投射(encoder)到隐空间、对encoder 的训练(对比损失函数)和下游任务优化4 个小部分。据上文中提到的对比学习的核心思想,本文把通过局部会话图学习到的目标物品的表示作为锚点(anchor),经过协同会话图学习到目标物品的表示作为相似样本(正样本),然后将经过协同会话图学习到的目标物品以外的物品表示作为不同样本(负样本)。对于相似度的定义,本文采用余弦相似度来衡量。由于每一个小批量数据集中包含大量的物品,每个给定的目标物品均包含大量的负样本,所以本文采用InfoNCE[20]损失函数作为自监督学习子任务的目标函数,计算方式如式(9)所示。
最终自监督学习的任务还要结合下游的任务效果,一起优化训练。这部分内容将在下文2.6 小节和2.7 小节进行详细的论述。
2.6 会话的表示学习
通过上文的自监督学习,得到的是会话中某一物品的表示。由于一个会话序列包含多个物品,所以需要把会话中每一个物品的表示进行聚合,进而生成整个会话的表示。
另外,在现实数据集中,可能存在2 个序列其节点顺序不同、但生成图的结构是相同的情况。例如会话序列1:[v1,v2,v3,v1] 和2:[v2,v3,v1,v2],经过2.1 小节的定义3 将生成相同的会话图,但是反映在真实序列中,不仅序列信息不同,用户当前兴趣点也不同。因此,考虑位置编码可以准确区分节点集合相同但顺序不同的同构序列图,对于学习图节点表示很重要。
本文引入位置向量(position embedding,PE)来学习准确的会话序列表示。对于会话S,其位置嵌入向量矩阵Ps为:Ps= {p1,…,pi,…,pt},其中pi∈Rd,变量t表示S的长度。位置嵌入向量矩阵的参数和2.3 小节的投影矩阵的参数一样,将通过端到端训练的方式与模型其他层的参数一起学习。最终融入位置编码信息的物品节点表示如式(10)所示。
其中W1∈Rd×2d是系数矩阵,evi是自监督学习得到节点vi的表示,pt-i+1是节点vi所在位置的位置编码向量,b1∈Rd为偏置,‖表示拼接函数操作。
对于会话序列,近期产生交互行为的物品节点更能反映匿名用户的当前兴趣[13],即会话序列中每个物品对于整个会话序列的表示贡献是不同的,因此模型采用注意力机制计算当前会话的各个物品节点对于整个会话表示的贡献度。计算方式如下:
其中W2,W3,W4∈Rd×d是系数矩阵,q,b2∈Rd是偏置,zvn是最近一次点击的物品节点的表示,z′为当前会话S所有物品节点表示的平均,计算z′是为了降低噪声数据的影响,表达式为
最终会话的表示S为
2.7 模型预测
根据2.6 节得到的目标会话S的表示S,为每一个候选物品vi∈V生成一个匹配得分,再用softmax 函数将得分归一化为推荐每一个候选物品的概率:
评分表示对于当前会话S,预测下一个产生交互的物品是vi的概率。本文通过优化概率最大的物品和实际下一个点击物品的交叉熵来训练模型,计算方式如下:
其中yi是训练数据中用户对物品vi真实的评分,是模型预测的评分。
另外,根据2.5 小节对自监督学习子任务的论述,通过自监督学习得到的物品表示是为下游的任务服务的,即2.6 小节的会话表示学习到2.7 小节的最终的模型预测(推荐任务)。所以本文采取的是端到端的训练方式,把自监督学习的子任务作为最终推荐任务的辅助任务,一起训练学习,使得模型能够解决单一会话中物品信息不足的稀疏性问题,更加优雅地聚合邻居节点的特征,优化物品的表示。最终多任务学习的联合训练损失函数为
其中,β 为超参数,Lr加号左侧的是推荐任务的损失函数,Ls是辅助任务的损失函数。
本节在3 个公开的真实数据集(Tmall、Diginetica 和Nowplaying)上进行详细的评估实验,并分析模型与基准方法的性能对比实验、消融实验和参数敏感度分析。
3.1 实验数据集和预处理
本文采用3 个公开的数据集,分别是Tmall、Diginetica 和Nowplaying。Tmall 和Diginetica 数据集分别是IJCAI-15 和CIKM Cup 2016 提供的电商平台中用户点击行为的数据集。Nowplaying 是音乐数据集,包含用户收听歌曲的行为数据。
数据预处理方式和基准模型[21-22]一致,首先过滤掉长度小于2 和物品出现次数少于5 的会话数据,然后进行数据增广,例如,输入会话序列S={vs,1,vs,2,…,vs,n},生成对应的序列和标签数据:([vs,1],vs,2),…,([vs,1,vs,2,…,vs,i],vs,i+1),其中[vs,1,vs,2,…,vs,i] 是输入序列,vs,i+1是对应标签;最后将最近1 周的数据作为测试数据,其余的作为训练数据。在经过上述预处理后,数据集统计信息如表1 所示。
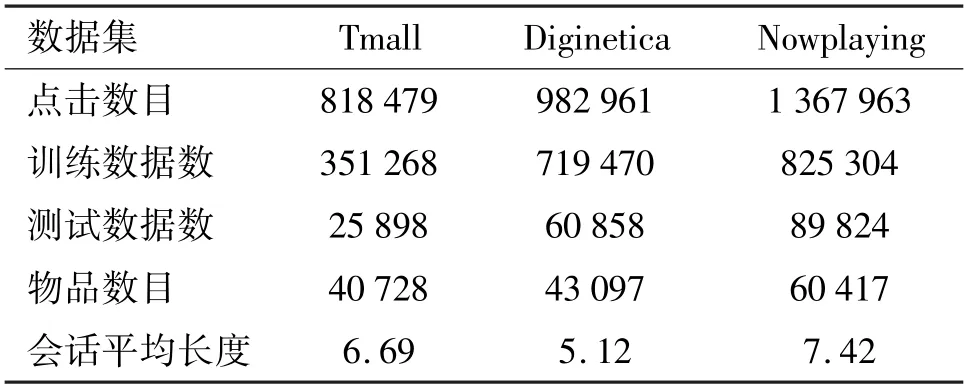
表1 数据集的统计信息
3.2 对比模型
为验证本文S-SGTN 算法的性能,与以下基线方法进行比较。
(1)POP:该传统的方法始终推荐当前数据集中出现频次最高的前N个物品。
(2)Item-KNN[23]:推荐与先前会话序列中物品相似的物品,相似度是2 个物品向量的余弦相似度。
(3)FPMC[7]:基于Markov 链的序列推荐算法。
(4)GRU4Rec[9]:将RNN 结构应用到SBR 中,用GRU 模块捕捉序列信息。
(5)NARM[22]:该算法在GRU4Rec 的基础上,融入注意力机制,并结合用户浏览时的顺序行为信息来建模SBR 以提升模型效果。
(6)STAMP[21]:应用自注意力机制建模会话的长期兴趣和短期兴趣,并通过提高短期兴趣的重要性来缓和兴趣偏移对推荐模型的影响。
(7)SR-GNN[11]:采用GGNN 学习会话内物品的表示,再结合注意力机制生成会话表示,并将最近一次行为物品作为短期兴趣,最后融合注意力机制生成会话表示,取得了显著的推荐效果。
(8)FGNN[24]:通过广义连接的会话图,丰富会话中物品的表示以提升推荐模型的效果。
3.3 评价指标
本文采用召回率(Recall@K)和平均倒数排名(mean reciprocal rank,MRR@K)评价指标。
Recall@K 表示推荐结果排名列表中排在前K的推荐物品中正确答案的数量占所有测试数的比重,是评价SBR 准确性的指标,计算方式如下:
其中,nhit表示目标物品包含在排名前K推荐结果中的情况数,N是测试集合会话序列数。
MRR@K 是排序指标,即前K个推荐结果中,所有目标物品在推荐列表中的排名倒数的加和平均,如果排名不在前K个推荐列表中,则取0。假设vtarget是目标物品,Rank(vtarget) 是目标物品在推荐结果列表中的位置。计算方式如下:
本文在评价模型性能时,采用的K值为20,因为在SBR 实际的应用场景中,绝大多数用户关注的重点是第一页的推荐结果。
3.4 参数设置
文中参数设置同文献[11]一致。在3 个数据集中,物品嵌入向量维度(hiddensize)d=100,数据集的批量(batch size)大小为128。模型使用Adam优化器,初始化的学习率为0.001,并在每3 轮训练以后,学习率按照衰减率0.1 进行衰减。为避免过拟合,L2 正则化设置为1e-5。本文设置K为20 来汇报模型性能。
3.5 实验结果
表2 记录了S-SGTN 模型和其他对比模型的实验结果。从实验结果可以分析得出如下结论。

表2 S-SGTN 和基线算法在3 个公开数据集的实验结果(%)
(1)传统算法(Item-KNN 和FPMC)性能低于基于深 度 学 习 的 SBR 算 法(GRU4Rec、NARM、STAMP、SR-GNN 和S-SGTN)。传统的方法无法充分捕捉会话的序列行为。由于Item-KNN 融入了物品之间的相似度信息,在Diginetica、Nowplaying 数据集上比FPMC 效果好,但在更复杂的数据集上,启发式的相似度方法表现不佳。
(2)GRU4Rec 作为第一个将RNN 应用到推荐系统中的模型,在Diginetica 和Nowplaying 数据集上效果比Item-KNN 效果稍差,因为Item-KNN 算法不仅考虑会话的序列信息,还考虑用户的兴趣迁移问题。NARM 和STAMP 算法在GRU4Rec 的基础上融入注意力机制来捕捉用户的兴趣,所以其推荐效果全面优于GRU4Rec。STAMP 在Tmall 数据集上的效果优于NARM,前者把会话序列中最近一次行为物品作为用户短期兴趣,证明在SBR 中,序列中不同物品对于会话表示的贡献不同,更凸显出用注意力机制捕捉用户兴趣迁移的重要性和有效性。
(3)基于GNN 的推荐算法(SR-GNN、FGNN 和S-SGTN)可以捕捉物品间高阶关系,与基于RNN 和注意力机制的方法相比,有较大的性能提升。因此,高阶转移关系在建模SBR 中非常重要。
(4)本文所提S-SGTN 算法融合会话内(local)和会话间(global)物品关联关系,并且采用对比学习的方式优化建模过程,在Tmall、Diginetica 和Nowplaying 3 个数据集上Recall@20 和MRR@20 相比于最好的基线算法分别提升16%和13.3%、5.7%和4.4%以及25%和13.9%。
3.6 协同信息建模和自监督学习的必要性
为验证S-SGTN 各个模块的性能,本文做了进一步的消融实验。
(1)S-SGTN_global:仅含local 模块物品特征,无global 模块物品特征。
(2)S-SGTN_local:仅含global 模块物品特征,无local 模块物品特征。
(3)S-SGTN-MIM:含有global 和local 模块物品特征,无自监督学习模块。
实验结果如表3 所示。表3 展示了不同子模块对模型的影响,根据结果可以得出如下的结论。

表3 不同子模块性能测试结果(%)
(1)在3 个数据集中,S-SGTN_global 实验结果优于S-SGTN_local。因为在会话序列中,用户兴趣往往是短期、动态变化的,并且对于当前会话来说,协同会话图中可能有些物品是噪声信息,稀释了当前会话信息,所以单独建模协同会话图比建模局部会话图性能要差。
(2)对于Tmall、Diginetica 数据集,S-SGTN_MIM 效果优于S-SGTN_global 和S-SGTN_local,说明在当前会话信息有限的情况下,融入协同会话信息是可行且有效的。在Nowplaying 数据集上,MRR有很大提升,Recall 反而下降,说明协同会话图的信息对于推荐结果的排序有指导意义,但对于当前会话,图中含有一定的噪声数据,所以对Recall 指标有一定程度的影响。
(3) 3 个数据集上,融合各个子模块的S-SGTN算法取得最好的效果。证实了自监督学习模块在融合同一会话中和不同会话间物品信息的重要性和可行性,其从2 个角度生成物品的表示,并互相成为彼此的自监督信号,优化推荐效果。
3.7 不同聚合函数对模型性能的影响性分析
本文分别采用加和(sum-pooling)、拼接(concatenation)、取最大(max-pooling)和线性组合(linear combination)的方式融合物品局部和全局的表示。实验结果如图3 所示。

图3 不同聚合函数模型性能图
实验结果表明,在3 个数据集中,4 种不同的聚合函数对模型性能的影响有显著的区别,其中加和的聚合方式取得了最优的效果。
因为目标物品在局部会话图中和协同会话图中生成的表示,虽然聚合的邻居节点信息不同,但实际上是同一个物品在2 个不同方面的表示,具有互补性。取最大值的聚合方式模型效果最差,因为取最大值的聚合方式损失了物品表示中的物品稀有特征,例如,长尾的物品特征。拼接的模型效果优于取最大值,但劣于线性组合的聚合方式。因为拼接的聚合方式重复建模了物品特征,淹没了长尾物品的特征。而线性组合的聚合方式采用注意力机制,用以生成局部和全局表示的权重,进而生成物品的特征表示,但其可能存在过拟合的问题,所以性能比加和的聚合函数效果差。本文采用的是加和的聚合函数,可看作是线性组合的聚合函数的特殊表现形式。
3.8 参数敏感度分析
本节结合实验分析,分别从训练数据的批量(batch size)、物品嵌入向量维度d、自监督学习辅助任务的超参数β、GTN 网络的丢弃率和层数L5 个角度讨论超参数对模型的影响。取值集合分别为[100,128];[64,100,128,256];[0.001,0.01,0.02,0.03,0.04,0.05];[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]和[1,2,3]。
具体的实验分析如下。
和先前的研究方法[11-16,21-22]一致,批量的大小设置为100 或者128。从图4 可以看出,当模型中训练数据的批量从100 调整为128 时,模型在3 个数据集上的性能都有提升。因为随着批量的增加,同一批次内物品的数量会有增加,对于降低噪声物品对目标物品的影响、聚合物品邻居节点的特征、建模物品之间的高阶转移关系和最终学习物品的embedding 表示都有一定的促进作用。
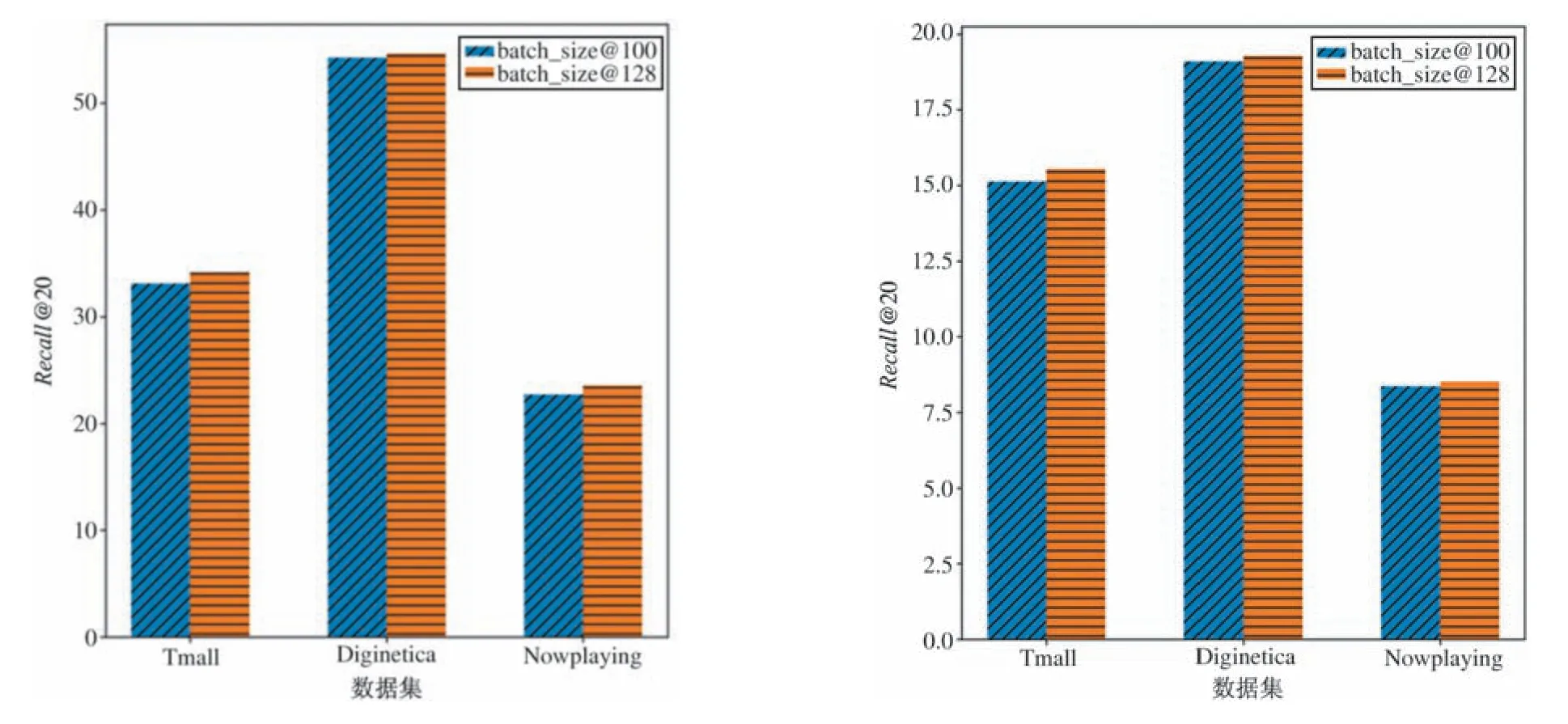
图4 不同批量对模型的性能影响图
本文分别取64、100、128 和256 四个数值,探索嵌入向量维度d对模型性能的影响。实验结果如图5所示。当物品嵌入向量维度d取值64 的时候模型效果最差,因为其不能完全表达物品的隐表示信息,物品特征有缺失。当取值100 的时候,模型取得最好的效果,并且随着嵌入向量维度d的逐渐变大,模型性能下降,因为随着隐表示维度的增加,会引入其他不相关的信息。
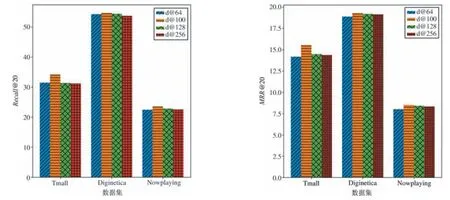
图5 不同嵌入向量维度对模型的性能影响图
在自监督学习模块,当β 取值不同,模型性能的变化如图6 所示。由图6 中可以看出,对于Tmall数据集,随着β 的不断增加,Recall@20 和MRR@20也随之增加,当β=0.03 的时候,模型效果取得整体最优,并且随着β 增大,模型性能下降,说明2 个任务在模型训练的时候存在梯度冲突。然而对于Diginetica、Nowplaying 数据集,分别在0.001 和0.02处取得整体最优的模型效果。故对于模型性能,需要找到合适的β 值,以获得Recall@20 和MRR@20指标之间的平衡。

图6 不同β 对模型性能的影响图
GTN 模块中,不同的丢弃率(drop out)取值对模型性能的影响如图7 所示。可以得到如下结论:对于3 个数据集,随着丢弃率取值从0.1 增加到0.9,Recall@20 和MRR@20 都呈现先增加然后降低的趋势;并且Tmall 在丢弃率为0.8 处取得最优的模型效果而Diginetica 和Nowplaying 分别在丢弃率为0.5 和0.2 时取得最优效果。最优取值不同,可能和会话序列的长度有一定的关系。
GTN 模块中,不同的丢弃率取值对模型性能的影响如图7 所示。可以得到如下结论:对于3 个数据集,随着丢弃率取值从0.1 增加到0.9,Recall@20和MRR@20 都呈现先增加然后降低的趋势;并且Tmall 在丢弃率为0.8 处取得最优的模型效果而Diginetica 和Nowplaying 分别在丢弃率为0.5 和0.2时取得最优效果。最优取值不同,可能和会话序列的长度有一定的关系。
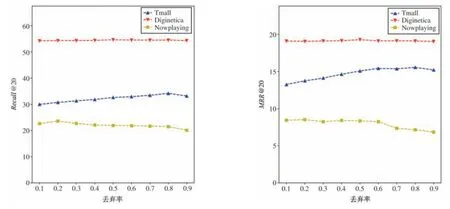
图7 不同丢弃率对模型性能的影响图
GTN 模块选取不同的层数L,对应模型性能变化如图8 所示。
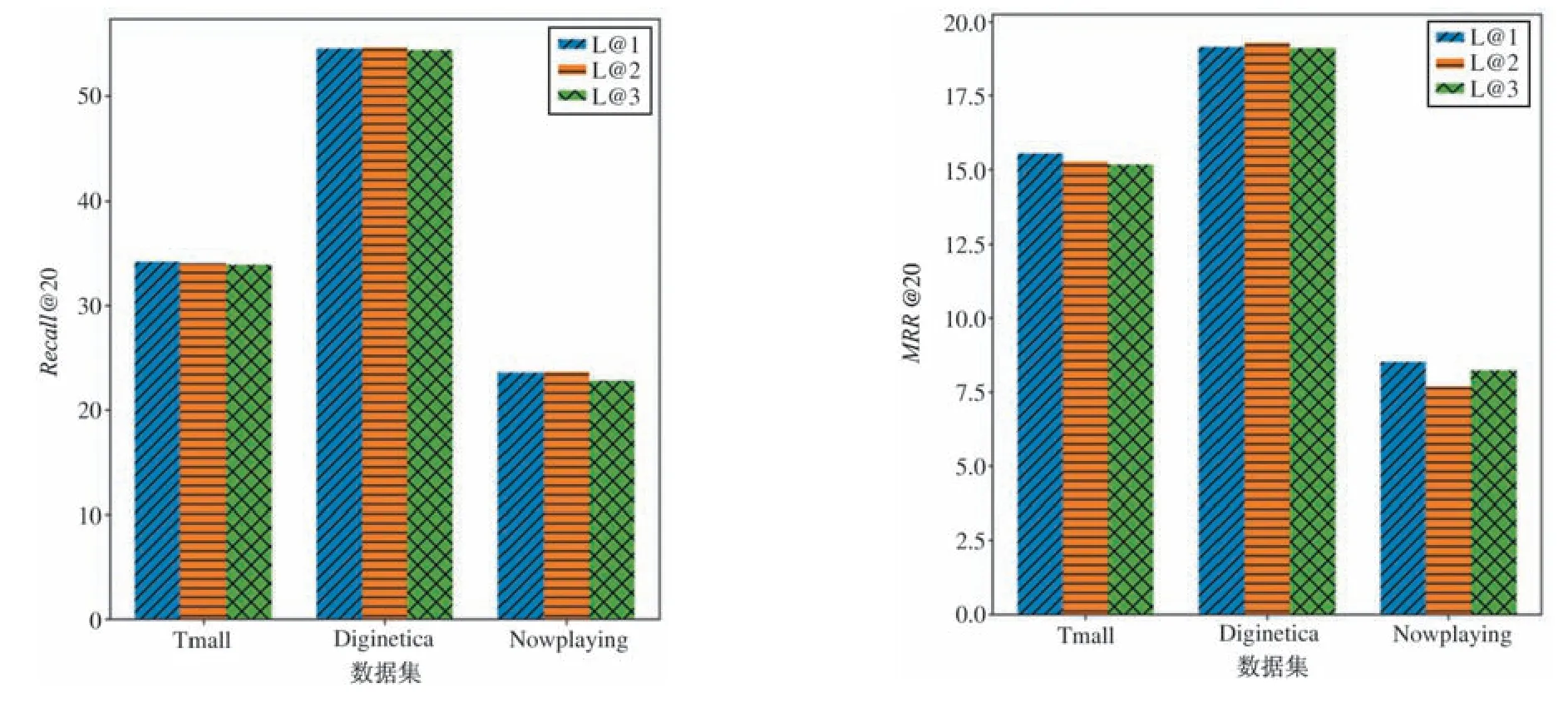
图8 不同GTN 层数对模型性能影响图
可以看出,Diginetica 数据集在层数L为2 的时候取得最优的效果,然而Tmall 和Nowplaying 数据集则是当L=1 的时候取得整体最优效果,且随着L的增大模型性能逐渐下降。因为随着GTN 网络卷积层数L逐渐增大,物品之间的表示会越来越接近,并趋于相同,即存在过平滑的问题。
3.9 模型性能效率
本文模型采用GCN 模型,计算的过程中可以并行以节省一部分计算时间。为了验证模型的运行效率,测试每轮次训练的平均耗费时长,并且与最优的基线算法模型SR-GNN 和FGNN 相比较,实验结果如表4 所示。
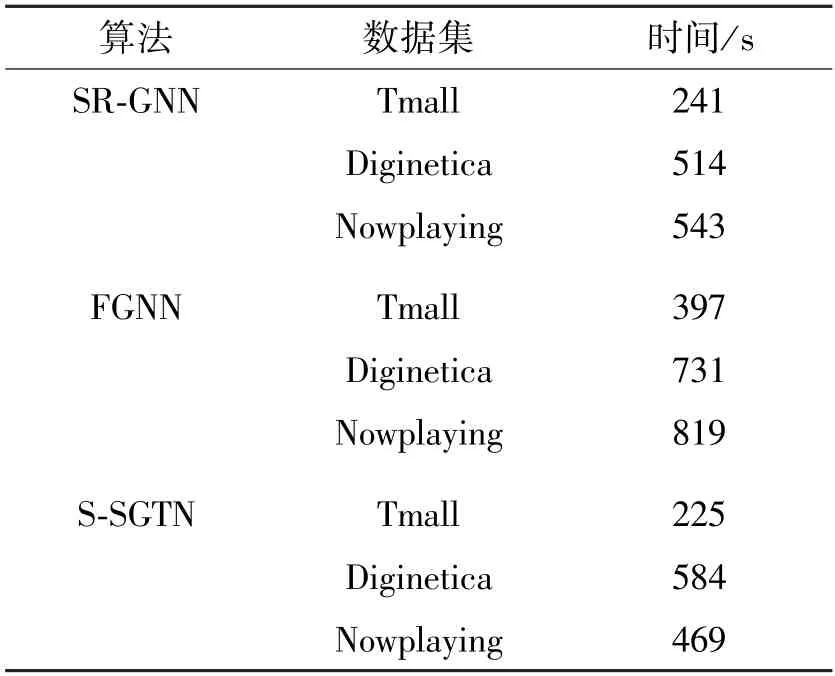
表4 每轮次平均训练时长耗费对比
实验结果表明,FGNN 整体训练时间最长,因为其结构中的图注意力网络每层都需要计算物品之间的权重,且层与层之间有依赖关系,不能并行处理。基于GCN 的S-SGTN 模型,因其具有独特的双通道结构,可以并行处理,因此S-SGTN 同时具备较好的模型效果和时间效率。
基于当前会话信息的推荐算法在建模物品和会话表示方面存在一定的局限性。每条会话都存在相似用户或相似意图的会话,这些会话中存在大量的协同信息,对这些协同信息进行有效融合是提升推荐效果的有效途径。
为了更准确地建模物品和会话的表示,本文提出一种基于自监督学习的图转移网络会话推荐算法。该算法从物品层面上利用双通道的图转移网络分别建模匿名用户会话内和会话间的物品转移关系,并在训练过程中,创建自监督学习的辅助任务,通过最大化会话内和会话间的物品表示的互信息,降低噪声信息对目标物品的影响,更好地聚合目标物品邻居节点的特征,动态生成物品和会话的表示,完成会话推荐。基于3 个数据集的结果证明了本文提出的算法的有效性。
猜你喜欢会话物品建模称物品小学生学习指导(低年级)(2022年5期)2022-05-31“双十一”,你抢到了想要的物品吗?疯狂英语·初中天地(2021年11期)2021-02-16联想等效,拓展建模——以“带电小球在等效场中做圆周运动”为例中学生数理化(高中版.高考理化)(2020年11期)2020-12-14QQ和微信会话话轮及话轮转换特点浅析长江丛刊(2020年17期)2020-11-19谁动了凡·高的物品少年漫画(艺术创想)(2019年2期)2019-06-06基于PSS/E的风电场建模与动态分析电子制作(2018年17期)2018-09-28不对称半桥变换器的建模与仿真通信电源技术(2018年5期)2018-08-23汉语教材中的会话结构特征及其语用功能呈现——基于85个会话片段的个案研究海外华文教育(2016年3期)2017-01-20找物品小天使·一年级语数英综合(2015年8期)2015-07-06三元组辐射场的建模与仿真现代防御技术(2014年6期)2014-02-28