无人驾驶规则的自动提取方法研究
黄治 周劲 何叶


摘 要:无人驾驶汽车的测试技术主要是通过虚拟测试和场地测试的方法来检测无人驾驶汽车的智能化水平,通过不断的学习和总结经验来提高无人驾驶的安全性, 这种方法耗费大量的人力物力以及时间。为此,从文本的角度出发,利用驾驶行为相关文本,通过NLP技术和基于规则的方法构建一个无人驾驶规则库,依据这个规则库来辅助测试无人驾驶汽车能否满足道路安全要求。实验结果表明,对《中华人民共和国道路交通安全法实施条例》处理后规则提取的正确率为 89.85%,驾考题库文本的正确率为87.33%。
关键词:驾驶规则库;自然语言处理;提取
中图分类号:TP181 文献标识码:A
Research on Automatic Extraction Method of Driverless Rules
HUANG Zhi1 ,ZHOU Jin1 ,HE Ye2
(1.State Grid Hunan Electric Power Limited Company,Changsha, Hunan 410014,China;
2.China Merchants Bank Network Technology Co. LTD,Shenzhen, Guangdong 518057,China)
Abstract:Nowadays, the test technology of driverless vehicle mainly tests the intelligent level of driverless vehicle by means of virtual test and field test, and improves the safety of driverless vehicle by continuous learning and summarizing experience. This method consumes a lot of manpower, material resources and time. Therefore, from the perspective of text, this paper uses the driving behavior related text, through NLP technology and rule-based method to build an driverless rule base, according to which to help test whether the driverless vehicle can meet the requirements of road safety. The experimental results show that the accuracy rate of rule extraction is 89.85% and the accuracy rate of driving test database text is 87.33%.
Key words:driving rule base; natural language processing;extraction
随着人工智能的不断进步和在汽车领域的应用,汽车的智能水平正逐步提高,无人驾驶汽车的测试方法也在不断的更新[1]。无人驾驶汽车作为解决智能交通、安全出行的重要方案,保证其不会造成交通事故并能够避免危险的发生是无人驾驶汽车测试的重要目标。
从已发布的无人驾驶汽车的安全性和可靠性评估中,为了测试事故率极低的目标汽车,仅道路测试就需要行驶不计其数的里程数[2]。而随着虚拟现实技术的发展,虚拟测试逐渐成为主流测试方法之一,对不同驾驶情况进行仿真,针对仿真结果来优化无人驾驶汽车[3]。一些测试研究人员从传统软件测试的角度出发,通过对交通规则进行形式化分析来对无人驾驶车辆行为进行验证。如文献[4]提出一种形式化方式来验证自动车辆安全性。文献[5]使用基于逻辑的方法,确定无人驾驶车辆在事故中应承担的责任。文献[6]利用线性时序逻辑(LTL)形式化了部分德国超车交通规则。目前国内对于交通法规在无人驾驶汽车测试方面的研究主要放在了无人驾驶汽车造成的犯罪和认定[7]。而对于交通法规上的应用,研究重点放在了信息的抽取和使用上,如文献[8]利用NLP技术构建了一个开源交通信息采集及分析系统来帮助道路的规划。
自然语言处理(NLP)相关的技术研究不断创新和发展,其应用也扩展到社会的各个方面。文献[9]通过Stanford NLP工具包对winemag网站上的7万多条葡萄酒评论,通过颜色、气味、城市等关键词进行文本分类处理,从而对葡萄酒进行评级。文献[10]开发一套自然语言处理工具,用于识别和注释意大利语文本报告中的各种考古实体。文献[11]利用NLP技术处理早期的软件需求,包括实現划分需求优先级和分类等目标,并提出了9种建议使用的NLP相关工具。而随着深度学习的研究并不断进步,人们利用深度学习的模型来解决各种NLP问题,并取得了巨大的成功。文献[12]总结了产生对抗性文本的最新方法,并提出了一个分类法来对文本进行分类。文献[13]提出了一个基于深度学习的NLP本体种群系统来填充生物分子网络本体,从文本数据中识别、提取和分类涉及生物分子网络本体概念的新实例。文献[14]利用神经网络在汉语分词中的应用,提出了一种利用高资源语料库改进低资源分词的转移学习方法。文献[15]对web上大量的医学诊断的相关信息进行提取,开发了一个智能系统,通过患者对病痛的描述,智能为患者推荐药物。文献[16]利用开放式信息抽取模型和词汇特征以及语义关系,从哈萨克双语新闻网站的文本中提取句子中的主谓宾,并以RDF三元组格式表示。
上述文献研究了无人驾驶汽车的测试方法和自然语言处理的应用,但是在国内并没有某项研究是利用交通法规来生成规则库来辅助无人驾驶汽车测试。因此本研究提出一种利用NLP技术和基于规则的无人驾驶规则库的生成方法。
1 相关研究
1.1 NLP
自然语言处理技术服务于大数据的文本处理,它的主要任务包括分词和词性标注,对句法、语义、篇章的分析,文本的分类以及自然语言的生成,以及信息的检索和抽取等等。自然语言处理的基础流程主要是下面五个步骤:
1)获取语料。语料是在实际生活中使用过的语言材料,语料的集合称为语料库。语料库就是一个电子文本集合。实验中的语料库来源主要有三种:一是公司或者组织积累或者整理的大量纸质材料或者电子文档;二是选择国内外研究人员归纳总结的开放数据集;三是通过爬虫,在网页中抓取自己所需要的数据。
2)语料预处理。对语料进行预处理主要包括四个步骤:语料清洗、分词、词性标注和去停用词。语料清洗是将现有语料中,不符合研究内容或者视为噪音的部分去除掉;分词主要是将句子拆分成一个个单独的词;词性标注是将每个词标注上词性标签,如a、v、p等等;清除停用词是将文本中一些标点符号、语气词、助词等不影响句子语义的词语去掉,方便之后处理,这一步骤是否需要根据任务目标来看。
3)特征化,也称为向量化。主要把字词表示成向量,这样可以通过计算机计算向量的偏差来表现不同词之间的相似性。在这个阶段常用是词向量和词袋模型(BOW)这两种方法。
4)模型训练。在构造好特征向量之后,使用不同的机器学习如KNN、K-meand或者深度学习模型如CNN、RNN、LSTM来进行训练。在实验主要通过调节参数来提高模型的泛化能力。
5)对模型的效果进行评估。主要通过准确率、召回率和F值等指标来衡量模型的好坏。
在驾驶规则库提取中,只进行了前两步流程,之后并未构建相应的模型,而是直接使用LTP训练好的数据模型对字词进行标注。
1.2 LTP
LTP语言技术平台(Language Technology Platform),是哈尔滨工业大学开发的一套中文语言处理系统,它包括了词性标注、角色标注等中文语言处理模块。并且LTP提供基于动态链接库(DLL)的API,网络服务以及可视化工具来分析结果。
LTP是一套高性能的中文NLP分析工具,它将一系列底层的自然语言处理任务进行封装,通过接口的方式对外提供服务,使上层研究人员可以在底层任务的基础上开始进行研究而无需训练相应的模型,节省了大量研究时间和减少了学习成本。针对除C++之外的不同开发语言,官方对LTP的接口进行了相对应的再次封装的,如Java语言的ltp4j,Python语言的PyLTP。本课题主要开发语言是Python,因此选择了PyLTP。在后续实验中,都将使用LTP工具进行分词、词性标注、语义角色标注等工作。
2 规则提取方法
2.1 驾驶规则提取流程
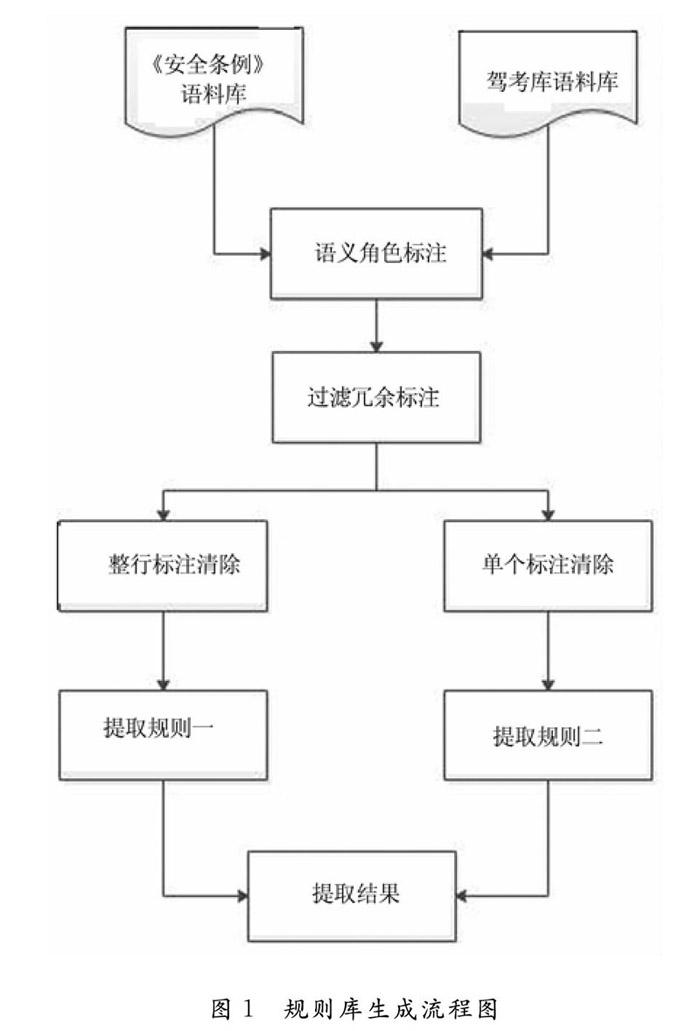
在获得文本的语料库之后,将对语料库进行语义角色标注,并对标注进行去冗余处理。在本课题的方法中,将给出两种去冗余标注的方法以及对应的提取规则。通过自定义提取规则对标注文本进行提取。
2.2 过滤冗余标注
LTP进行角色标注的结果是有多种情况的,且存在同一条语料在不同标注场次有不同结果,只有先选出最完整的能够准确表达语义的标注,才能进行之后的分析。这一步至关重要,因为如果缺少句子成分,那么之后的提取变得毫无意义。这种影响语义理解的标注结果我们称之为错误角色标注。下面提供了两种过滤冗余标注的方法。
方法一:整行标注清除。
该方法主要是用于从多行标注结果中选择出最合适的一条或者几条标注。该方法主要实现逻辑如下:
1)保存每一个role的最小序列号start和最大序列号end,作为下一个role的min、max的数值。
2)当满足start <= min<= max <= end 時,表示上一个role的内容不如当前role,删除掉上一轮role。
3)当满足max >= end 时,说明这个标注的区间已经在上一个role中存在了,舍弃这个标注。
4)对角色标注有错误的语料打上标记,输出过滤结果。
方法二:单个标注清除。
与方法一删去整一条role不同,该方法对每一条role中的标注进行判断,最后得到的结果中没有重复的标注区间。该方法主要实现逻辑如下:
1)将多个role中的标注都放到词典中,以动词序列+短语起始序列+短语终止序列号为键,以标注+标注区间为值。
2)当某个区间是另一个区间的子集,删除该区间。
3)重新构建role数据格式,每个role中按标注区间的起始序号升序排序。
4)对角色标注有错误的语料打上标记,结果role按动词序列升序排序,输出结果。
2.3 提取规则
根据过滤冗余标注的第一种方法——整行标注清除法,该方法会对整行标注进行删除,它的结果特点在于在去重的基础上最大化的保留了原始的角色标注结果。根据标注过滤结果的特点进行分析,可以构建相应的提取规则来提取条件短语和行为短语。提取规则一流程如图2所示。
根据过滤冗余标注的第二种方法——单个标注清除法,该方法对全部的标注进行了筛选、排序,并重新构建输出格式,这样的结果去除了重复成分,且按照词语的初始序列范围的初始序列来对标注排序,保证了词语标注在原语料中的顺序。单个标注清除法得到的结果标注可以分为两类处理,一类是只有一行role的情况,另一类是有多行role的情况。这两种提取流程组成提取规则二。
当标注结果只有一行role时,驾驶条件和行为的提取流程如图3所示。
当结果是有多行role时,不用再单独考虑每一类标注类型,直接利用标注和词语特征提取条件和行为短语。每一行role的处理如流程图4所示。
2.4 提取后处理
在根据角色标注特征将短语放入条件队列和行为队列之后,可以根据自定义的条件词词典和行为词词典对结果进行进一步分类处理。由于在过滤冗余标注处理中,动词并未进入去重标准,因此存在多余的动词,所以需要对条件队列和行为队列中的短语去重。并且可以删除“驾驶人”、“驾驶人要”这种主语或者主谓短语等等无效词,这些词语的去除不会影响提取结果,保留下来拼接语句时反而导致语句不通顺。
2.5 标注错误语句处理方法
由于在过滤冗余标注阶段,被标记为错误标注的句子过多,针对这些句子继续提取驾驶条件和行为。观察文本发现以‘,为分割符对句子分块,大多数情况下,最后一块的短语一定是驾驶行为,并且部分句子以逗号分隔条件和行为,如“准备超车,应当提前开启左转向灯。”,逗号之前是条件,逗号之后是行为。而对于除最后一块短语的前面所有的语句块先全部看做驾驶条件。之后,通过行为词词典构建正则表达式,将捕获到行为词的条件队列中的语句块移动至行为队列中。
3 实验结果
3.1 数据获取
从华律网中的民商法类部分,通过直接复制文本的方法获取到《安全条例》文本,获取的文本存为TXT格式。
驾考题库文本的获取,可在聚合数据官网注册登陆之后,申请唯一appKey作为用户凭证,之后进行数据请求获得所有题库,以JSON形式存储。
3.2 预处理
《安全条例》中部分文本与驾驶规则无关,部分条例是关于非机动车、行人等等,这些内容直接过滤。之后对剩余的文本进行标准化处理,主要过程如下:
分句。对于一条安全条例,可能存在多个句子。因此,以标点符号“。”或者“;”来切分句子。
关联语句处理。在一些安全条例中可能存在在多类条件下,车辆需满足的同一驾驶行为。比如:“机动车在行驶过程中遇到以下情形之一时”。这需要将多类条件与相应行为合并成一条语句。也可能存在一个大条件下,多个小条件下的驾驶行为,如:“机动车转弯时要恪守以下规定”等条例。处理文本时,将大条件放入每一条规定的最前面。
句子拆分。条例中当有多个并列词语时,将其拆成多个以并列词之一为主语的句子。一般来说,并列词语都是以“、”分隔词语,当分隔词之间是“或”的关系,就可通过字符串切割加文本拼接进行处理,然后人工调整结果。但如果词之间是“与”的关系,就不能拆分,而是作为一条语句处理。
去除多余主语。在文本中,所有的行为的发起者都是机动车,因此去除“机动车”不会影响语义,且有利于之后的语义角色分析的准确度。
而关于驾考题库的预处理,由于图片无法处理,所以JSON数据中的图片类型的题目不在本课题研究的考虑范围内。其次,很多驾考题目是关于扣分、罚款的刑罚条例,驾驶人基本储备知识,以及一些危险操作的危害等,这些与本课题的研究的驾驶行为关系不大,均通过过滤词将这些题目过滤掉。之后通过答案映射表,将每条数据的question字段和answer字段进行拼接,将问题和答案合并成一条通顺的语句。这个过程主要通过正则表达式的匹配和字符串的拼接来进行。
在对文本进行过滤和标准化之后,即可利用LTP工具进行分词,在分词后将驾驶专业术语重新拼接,之后进行词性标注,至此,我们得到了《安全条例》语料库和驾考题库语料库。
3.3 实验结果
1)《安全条例》文本规则提取结果
注意:上表中标注错误语句条数的数量在±2中浮动,错误提取语句条数也在±2中浮动。
从实验数据来看,由于《安全条例》文本数量较少,两种方式的规则提取正确率差别不大。但从结果来看,对《安全条例》文本的规则提取选择方式一,即整行标注清除的方法清除冗余标注,并选择相对应的抽取规则一。
发现标注错误语句中可正确提取语句的情况如表2所示。
經过方式一对文本进行规则提取,并对LTP工具标注错误的语句进行进一步处理,最终从《安全条例》文本中提取规则的情况如表3所示。
通过处理,最后对《安全条例》文本的驾驶规则提取准确率为89.85%。
2)驾考题库文本规则提取结果
注意:上表中标注错误语句条数的数量在±4中浮动,错误提取语句条数也在±4中浮动。
综上数据,对驾考题库文本的规则提取选择方式二,即单个标注清除的方法清除冗余标注,并选择相对应的抽取规则二。
对标注错误的语句进行处理后得到数据如表5所示。
经过方式二对驾考题库文本进行规则提取,并对标注错误的语句进行了进一步处理,最终从架考题库文本中提取规则的情况如表6所示。
由实验结果可知,经过处理,对驾考题库文本的驾驶规则提取准确率提升为87.33%。
3.4 驾驶规则库展示
驾驶规则库最终可展示为两种形式,一种是以TXT文件形式存储驾驶规则,另一种则是在数据库中存储,后者主要是为了之后方便利用提取的规则数据。TXT文件形式如图5所示。
4 结 论
主要对无人驾驶规则库的规则提取方法进行研究。通过网页爬虫和API接口调用获取了《安全条例》和驾考题库两类与交通规则相关的文本,通过选定过滤词典将不相关的文本去除,最后通过人工和程序对现有文本进行标准化。之后通过哈工大语言技术平台LTP中已经训练好的数据模型对语料进行分词和词性标注处理。通过基于规则的方式对语料标注结果进行驾驶条件和驾驶行为的提取。提出了两种过滤冗余标注的方法,并针对不同的方法处理的结果,又提出了两种相应的提取规则。实验数据表明,该方法在驾驶规则的提取上取得了不错的效果,也为后续无人驾驶测试工作提供一条新思路。
本研究仍存在一些不足,如LTP工具在角色标注方面存在着不确定性,对提取规则的准确率有限制。之后可以尝试使用其他的语言处理工具如 ICTCLAS、HaNLP、斯坦福分词系统等等。另外,提出的方法对一些特殊的句子无法进行提取,之后可以扩充相应的提取规则或者使用其他方法来优化系统。其次,本研究只对《安全条例》和駕考题库进行了处理,在以后的研究中,要扩充语料的来源。比如可以针对错误的行为进行相应的提取,并且可以从交通事故等文本中来提取驾驶规则。
参考文献
[1] 吴海飞,宋雪松,曹寅. 自动驾驶汽车测试评价方法体系研究[J]. 质量与标准化, 2018, (5):50-52.
[2] 范志翔,孙巍,潘汉中,等.自动驾驶汽车测试技术发展现状与思考[J].中国标准化,2017,(20):47-48.
[3] ZHANG Shou-wen, HU Jia-hao, WANG Zi-ran. Autonomous-driving vehicle test technology based on virtual reality[J].The Journal of Engineering, 2018, (16):1768-1771.
[4] ALTHOFF M, JOHN M. D. Online verification of automated road vehicles using reachability analysis[J]. IEEE Transactions on Robotics. 2014,30(4):
903-918.
[5] RIZALDI A,MATTHIAS A. Formalising traffic rules for accountability of autonomous vehicles[C]. IEEE 18th International Conference on Intelligent Transportation Systems,2015:
1658-1665.
[6] RIZALDI A, KEINLOLZ J. Formalising and monitoring traffic rules for autonomous vehicles in Isabelle/HOL[C]. International Conference on Integrated Formal Methods 2017:
Integrated Formal Methods ,2017:50-66.
[7] 时怡.自动驾驶汽车的交通事故责任分析及规则应对[J].六盘水师范学院学报,2019,31(05):72-78.
[8] 吕宜生,陈圆圆,赵学亮,等.开源交通信息获取及分析系统[A]. 2017中国自动化大会(CAC2017)暨国际智能制造创新大会(CIMIC2017)论文集[C]. 2017:942-949.
[9] HENDRICKX I, LEFEVER E, CROIJMANS I, et al. Antal van den Bosch:very quaffable and great fun:
applying NLP to wine reviews[C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016:306-312.
[10]FELICETTI A, WILLIAMS D, GALLUCCIO I, et al. NLP tools for knowledge extraction from Italian archaeological free text[C]. 2018 3rd Digital Heritage International Congress (Digital HERITAGE) held jointly with 2018 24th International Conference on Virtual Systems & Multimedia (VSMM 2018), San Francisco, CA, USA, 2018:
1-8.
[11]NAZIR F, BUTT W H, ANWAR M.W, et al. (2017) The applications of natural language processing (NLP) for software requirement engineering -a systematic literature review[C]. In:
Kim K., Joukov N. (eds) Information Science and Applications 2017. ICISA 2017. Lecture Notes in Electrical Engineering, Springer, Singapore,2017,424:1-10.
[12]ALSHEMAL I, JUGAI KALITA B.Improving the reliability of deep neural networks in NLP:
a review[J]. Knowledge-Based Systems,2020,105210 :1-19.
[13]AYADI A, SAMET A, ZANNI-MERK C.Ontology population with deep learning-based NLP:
a case study on the Biomolecular Network Ontology[C]. 23rd International Conference on Knowledge-Based and Intelligent Information & Engineering Systems,KES:2019:
572-581.
[14]XU Jing-jing, MA Shu-ming, ZHANG Yi, et al. Transfer deep learning for low-resource Chinese word segmentation with a novel neural network. NLPCC 2017:
721-730.
[15]PRIYADARSHI A, KUMAR SAHA S.Web information extraction for finding remedy based on a patient-authored text:
A Study on Homeopathy[J]. NetMAHIB,2020, 9(1):
1-12.
[16]KHAIROVA N, PETRASOVA S, MAMYRBAYEV O, et al. Open information extraction as additional source for Kazakh ontology generation[J]. ACIIDS ,2020:
86-96.