基于XGBoost,和改进LSTNet,的气温预测设计
陈 岚, 张华琳, 汪 波∗, 文 斌, 邱丽霞, 段 卿
(1.成都信息工程大学 通信工程学院, 四川 成都 610225;2.福建省气象信息中心, 福建 福州 350025)
随着气象服务业的发展,精细化和超前化的气象服务对气温数据预测的精确度和时效性要求越来越高。
气温预测已经从最早的天气图预测,发展为目前以数据驱动为主的预测。
数据驱动目前应用最广泛的有统计方法和人工智能方法2 种,很多学者已经进行了一系列研究并取得了显著成效。
汪子琦等[1]基于向量自回归的组合模型来分析气候变化,并添加月份为外生变量来消除时间趋势影响,从而建立了气候预测模型;王源昊[2]结合了集合经验模态分解和整合移动平均自回归来对平均气温进行建模;吴永涛等[3]利用支持向量机(Support Vector Machines,SVM)预测未来一天的最高和最低气温;蒋艮维[4]通过粒子群优化算法对人工神经网络进行优化,建立气温预测模型;陶晔等[5]利用随机森林和长短期记忆(Long Short-Term Memory, LSTM)网络建立气温预测模型。
上述模型虽然都取得了不错的效果,但也存在一定缺陷,如差分整合移动平均自回归模型相结合的方法忽略了其他气象要素对气温的影响;向量自回归、SVM 和人工神经网络这三者在模型训练过程中仅将历史数据进行统一输入,未充分考虑气温序列随时间的变化趋势。
并且上述模型大多支持单步预测,多步预测时效果不理想,满足不了目前精细化、未来化的气温预测要求。
为此,本文提出一种融合极端梯度提升树(Extreme Gradient Boosting,XGBoost)和改进长短期时序网络(Long and Short-Term Temporal Patterns with Deep Neural Network,LSTNet)的气温预测模型,记为XGBoost-TCA-LSTNet。
首先,利用XGBoost 可以衡量各特征重要性的特点来进行特征筛选;然后,对LSTNet[6]进行改进,在卷积模块的一维卷积[7]中嵌入通道注意力(Channel Attention,CA)机制[8],解决了传统卷积中每个通道占比相同时带来的重要信息损失的问题;在循环模块和循环跳接模块中用双向长短时记忆(Bidirectional Long Short-Term Memory,BiLSTM)网络替代原始循环门单元(Gate Recurrent Unit,GRU),弥补了GRU 无法捕捉反向时间序列信息的不足。
然后在BiLSTM 侧加入时序注意力(Temporal Attention,TA)机制[9],突出重要时间步的特征。
最后,用建立好的模型进行仿真实验和对比实验,验证模型的性能。
1.1 XGBoost 算法
XGBoost 是梯度提升树算法的改进[10]。
XGBoost 算法具体可表示为:
式中,y(N)k是最终回归结果;N表示决策树的数量;fN(xk)表示第k个样本xk在第N棵树中的预测值,再叠加前面N-1 次的预测值就得到最终的预测结果。
可以看出,XGBoost 遵循先迭代第1 棵树,再迭代第2 棵,直到迭代完第N棵树。
每棵树都是通过学习前(N-1)棵树的残差来最终构成由N棵树线性组合而成的模型[11]。
XGBoost 算法选择最优特征子集的原理如下:在单个决策树中,利用每个属性分割点改进性能度量的量来计算属性重要性,由节点进行加权和记录次数[12]。
一个属性对分割点改进性能度量越大,权值越大,属性越重要[13]。
最后将属性在所有提升树中的结果进行加权求和并平均,得到重要性得分,即Fscore。
Fscore 也可以理解为特征在决策树里出现的次数,一般来说,如果一个特征在所有树中作为划分属性的次数越多,那么该特征就越重要。
Fscore 计算如(5)所示,式中M是所求特征分类到节点的集合:
1.2 LSTNet
LSTNet 网络由线性和非线性2 部分组成,如图1所示。
非线性部分包括卷积模块、循环模块和特殊的循环跳跃模块,线性部分则由自回归模块组成,这样的组合可以成功捕获数据中的长期模式和短期模式,使模型更加稳健[14]。

图1 LSTNet 结构Fig.1 LSTNet structure
非线性部分中,以多元时间序列作为卷积模块的输入,卷积模块采用去除了传统池化层一维卷积,负责捕捉多个变量之间的依赖关系以及时间维度中每个变量自己的短期局部特征。
式(6)表示第n个滤波器对变量矩阵X 进行卷积:
式中,卷积运算后输出的特征向量即hn;ReLU 是激活函数;Wn表示卷积核的权重矩阵,连接到第n个特征图即Wn;X 为卷积模块的输入向量;bn为偏置。假设有i个滤波器,经过卷积模块后会输出大小为i∗j的特征向量,j是X 经过第一个卷积核后产生的向量的长度[15]。
卷积层输出后的数据下一步会同步进入循环模块和循环跳接模块,本文在循环模块和循环跳接模块都使用LSTM 作为基本单元,二者在t时刻单元状态的更新可以统一表达如下:
式中,q为跳过隐藏层的数量,需要根据时间序列明显的周期模式进行调优;ft,it,gt,St,ot,ht分别为遗忘门、输入门、输入节点、记忆单元、输出门以及隐含层输出;W 为相应门与输入相乘的权重;b 为相应门的偏置向量;“·”表示向量的元素按照相应的位置相乘;σ,tanh 分别表示Sigmoid 函数、双曲正切函数。
接下来是利用全连接层把循环和循环跳接模块的输出进行整合,至此非线性部分结束。
线性部分是通过引入自回归AR,为预测添加线性部分。
在某些数据并不具有很强的周期性时,只用非线性部分进行预测,效果不理想,实验发现加入线性预测部分后,可以弥补神经网络模型在非周期变化预测精度低的不足[16]。
自回归部分为:
2.1 改进的LSTNet
本文对LSTNet 的改进如下:
① 在循环模块和循环跳接模块中,原始LSTNet采用GRU 作为基本单元,只能考虑单向的数据信息,忽视了序列的反向信息对预测的影响。
对此,本文提出用双向循环神经网络BiLSTM 代替GRU,方便同时提取双向的数据信息,以期获得更好的预测效果。
BiLSTM 由正向LSTM 和反向LSTM 两部分组成,然后前馈到同一个输出层,可以理解为彼此之间相互独立且数据流向相反的网络进行组合,即完全独立的2 个隐含层[17]。
图2 为BiLSTM 在t-1,t,t+1 时刻沿时间轴展开的结果,其中模型输入为Xt,正向隐藏层状态为At,反向为t,最终输出由At与t共同决定。

图2 BiLSTM 展开结构Fig.2 BiLSTM deployment structure
② 在卷积模块引入CA 机制。
传统卷积层提取信息时,特征图的各通道分配权重相当,而事实上,不同通道中蕴含信息的重要程度不同,这样就造成了重要信息的流失[18]。
为了加强模型对重要通道特征的学习,本文提出的模型在卷积神经网络(Convolutional Neural Network,CNN)中加入注意力机制,将不同通道赋予各自的权值,形成CA 机制最后将所有通道信息加权求和,得到卷积层输出,具体如图3 所示。

图3 带有注意力的卷积层结构Fig.3 Structure diagram of convolution layer with attention
③ 在循环模块和循环跳接模块引入TA 机制。无论是GRU 还是BiLSTM 作为基本单元,针对较长时间序列的记忆时,都会出现信息损失[19]。
为了在挖掘时间序列的依赖关系时,突出重要时间步的信息,本文在BiLSTM 侧嵌入TA 机制,注意力机制结构如图4 所示。
Yt表示BiLSTM 输出的第t个特征向量,Yt经过注意力机制层后得到初始状态向量Zt,然后再和权重系数∂t对应相乘相加得到最终输出向量O 。
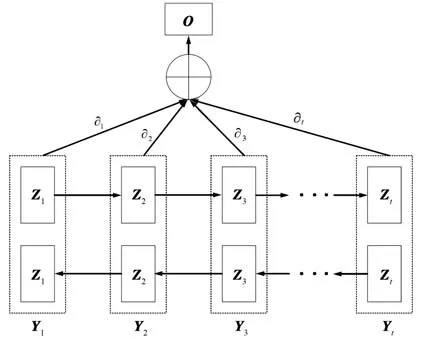
图4 带有注意力的BiLSTM 结构Fig.4 Structure diagram of BiLSTM with attention
综上所述, 改进后的 LSTNet 结构如图5所示。

图5 改进LSTNet 结构Fig.5 Structure diagram of improved LSTNet
2.2 基于XGBoost 和改进LSTNet 的气温预测模型
基于XGBoost 和改进LSTNet 的气温预测模型的预测步骤如图6 所示。

图6 模型预测步骤Fig.6 Model prediction steps
① 先对获得的原始气象数据进行简单清洗,去除重复值,填补缺失值;
② 然后对数据进行归一化,并以气温为预测的目标要素,利用XGBoost 进行输入特征选取;
③ 确定目标要素和特征要素后,根据跳跃步长q将数据集划分为2 个新的数据集,分别作为循环模块和循环跳跃模块的输入;
④ 利用改进LSTNet 模型进行单步和多步训练、测试,然后将预测结果反归一化得到最终预测结果;
⑤ 将预测值与真实值进行对比,通过评估指标来评估模型单步和多步预测的性能。
3.1 数据预处理和模型参数确定
本文实验数据来源于福建省福州市平潭县平潭地面观测站的小时观测数据,数据真实可靠,来源具有合法性。
在数据清洗时,对重复数据采取直接删除的方法,对缺失数据,利用临近数据的均值进行填充,保证数据的完整性。
划分数据集时,将预处理后的数据按照4 ∶1 的比例划分训练集与测试集。
然后按照式(15)对数据进行归一化处理。
式中,a∗为标准化后的结果;a为某特征原始数据;min为特征a的最小数值;max为特征a的最大数值。
此外,针对LSTNet 网络的预测效果与时间窗宽度t和跳跃时间步q有关的问题,经多次实验参数寻优后发现,当窗宽为7,跳跃步长为4 时,模型可达到最优效果,因此本文的时间窗宽度设置为7,跳跃步长设置为4。
3.2 评价指标
为了评价模型对气温预测效果,本文选取了均方根误差(RMSE)和平均绝对误差(MAE)2 个指标作为评估指标,公式如下:
式中,N为选取的样本数量;y′i为预测值;yi为实际观测值。
3.3 实验结果与分析
3.3.1 特征工程结果及有效性分析
特征过多时会增加算法复杂度,增加模型训练和预测时间,因此在模型训练之前,有必要进行特征选择。
常见的特征选择方法分过滤型、包裹型、嵌入型三大类。
本文选用了嵌入型方法,并采用XGBoost 进行特征选择,并以XGBoost 中内置的特征重要性评分指标Fscore 来度量特征重要性。
相较于皮尔逊相关系数、斯皮尔曼相关系数和互信息法等传统的利用相关性分析来进行特征选择的方法。
用XGBoost 进行特征选择好处在于,不必像皮尔逊相关系数一样受限于样本量以及样本是否满足正态分布,适用性更强;且使用这种梯度增强类的决策树模型做特征筛选时,可以从训练有素的预测模型中自动提供特征重要性的估计,在特征筛选和模型可解释性等方面比斯皮尔曼相关系数和互信息法都有显著的优势。
最后,XGBoost 算法自诞生之初就具有训练速度极快、能处理大规模数据的特点,本文涉及15 个特征以及上万条小时数据,因此XGBoost 会更适合这种大规模数据集的特征选择问题。
综上,选用了XGBoost 作为特征选择的方法。
下面是利用XGBoost 方法计算得到的各个特征重要性得分Fscore,如图7 所示。
为了充分考虑特征多样性和尽可能降低模型复杂度,本文将筛选界限设置为240,即选择Fscore 值大于240 的气象要素,和历史气温数据一起作为预测模型的输入,如图8 所示。
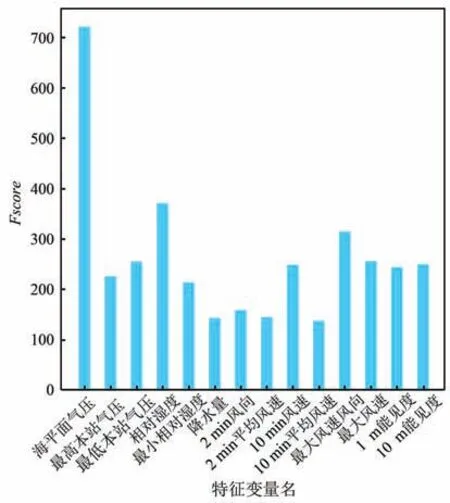
图7 特征重要性排序Fig.7 Feature importance score
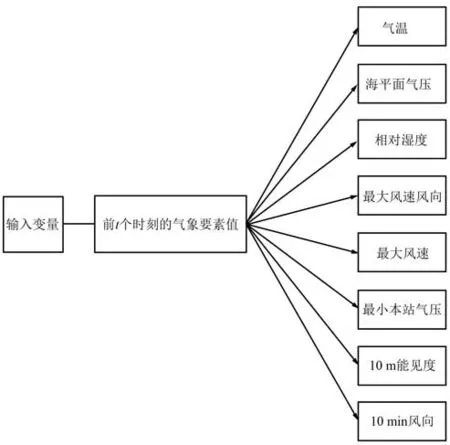
图8 模型输入变量Fig.8 Model input variables
此外,为了验证XGBoost 方法进行特征选取对LSTNet 网络的有效性,将LSTNet 模型和改进的LSTNet 模型设为预测模型,然后以XGBoost 方法选取后的特征和未经过筛选的特征分别作为模型的输入,进行单步预测(预测未来1 h 的气温),测试结果如表1 所示。

表1 XGBoost 方法有效性测试结果Tab.1 Effectiveness test results of XGBoost method单位:℃
由表1 可以看出,经过XGBoost 方法特征提取后,原LSTNet 模型的RMSE 减小了8.6%,MAE 减小了8.1%;改进后的LSTNet 模型RMSE 减小了9.8%,MAE 减小了9.2%,说明利用XGBoost 进行特征提取的方法适合LSTNet 和改进后的LSTNet 模型,输入特征量的降维优化有利于提高模型预测精度。
3.3.2 气温预测结果分析
为了验证XGBoost-TCA-LSTNet 模型对气温预测的准确性,选用SVM 模型、lasso 回归模型、BP 神经网络、LSTM 模型、CNN-LSTM 模型和原始LSTNet 模型为对比模型,进行单步预测(预测未来1 h 的气温数据),预测结果与XGBoost-TCA-LSTNet 模型对比。
上述模型实现都在keras 和sklearn 下进行,SVM 以径向基函数作为核函数,惩罚系数为8,不敏感系数设为0.15;BP 神经网络的学习率设置为0.01,隐藏层神经元数量设置为32,批处理数量为64,最大迭代此时为400 次。
2 层结构的LSTM 模型神经元数量为32 和48;CNN-LSTM 模型中一维卷积层的卷积核个数为128,大小为3×3,LSTM 层的神经元数量为64;LSTNet 模型和XGBoost-TCA-LSTNet模型的窗宽仍为7,跳跃步数为4。
所有模型都在训练集训练,保存最优模型后,再在测试集上进行测试。
由于样本数据量较大,为了更清晰地展示实验效果,在测试集中随机选取183 条数据进行展示,结果如图9~图15 所示。

图9 SVM 测试结果Fig.9 SVM test results
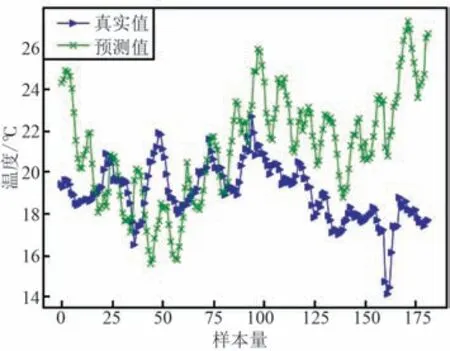
图10 lasso 测试结果Fig.10 lasso test results

图11 BP 测试结果Fig.11 BP test results
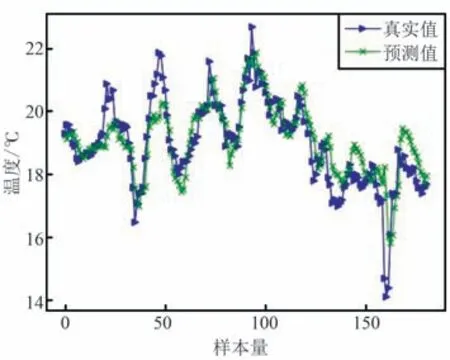
图12 LSTM 测试结果Fig.12 LSTM test results
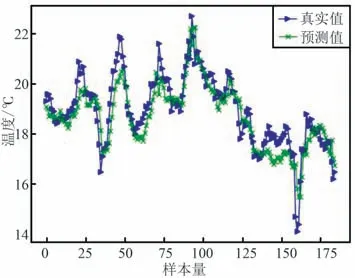
图13 CNN-LSTM 测试结果Fig.13 CNN-LSTM test results

图15 XGBoost-TCA-LSTNet 测试结果Fig.15 XGBoost-TCA-LSTNet test results
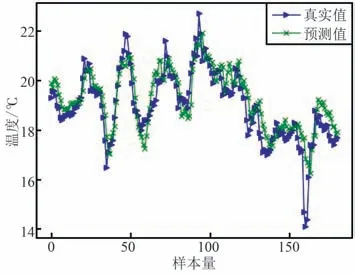
图14 LSTNet 测试结果Fig.14 LSTNet test results
从图9~图15 可以看出,SVM,lasso 回归和BP神经网络的预测值与实际气温值相差较大,表现远不如其他4 种模型,这是因为其他4 种模型都含有循环神经网络的变体LSTM 或者GRU,使得模型对早期数据具有记忆功能,能够发现相对较长时间序列的内部变化规律,而SVM 和BP 不具备这种特性。
此外,LSTM,CNN-LSTM 以及原始LSTNet 模型在气温波动较大的地方拟合效果并不好,如从样本量45~50 以及样本量150~165 这2 个数据段,当气温剧烈突变时,3 个模型预测出的气温值与实际气温值相比都有较大偏差。
而XGBoost-TCA-LSTNet模型在整个数据段,与真实的气温数据贴合程度都相对较高,在部分数据段,预测气温值与真实气温几乎完全重合,说明XGBoost-TCA-LSTNet 模型对非线性、非平稳变化的气温数据动态跟踪能力更强。XGBoost-TCA-LSTNet 和其他模型单步预测的评估指标如表2 所示,可以发现XGBoost-TCA-LSTNet 模型预测误差最小,精度最高。

表2 不同模型多步预测误差对比Tab.2 Comparison of multi-step prediction errors of different models单位:℃
为了证明XGBoost-TCA-LSTNet 模型在气温多步预测方面的优势,对气温进行最高9 步的多步预测,即预测未来9 h 内气温的变化趋势。
4 种模型的多步预测时评估指标的具体数值如表2 所示,评估指标随时间的变化情况如图16 和图17 所示。

图16 不同模型预测RMSEFig.16 RMSE of different models

图17 不同模型预测MAEFig.17 MAE of different models
可以看出,随着时间步的增加,各个模型RMSE和MSE 都逐渐增大,但总体上XGBoost-TCA-LSTNet的预测误差仍然比其他6 种模型小。
这说明文中提出的模型在气象数据这种气温这种时间序列的多步预测中表现更好,对数据突变更敏感,动态跟踪能力和适应性更强。
综上所述,对非线性、动态变化频繁气温时间序列预测而言,采用本文的XGBoost-TCALSTNet 模型效果更好。
本文提出的XGBoost-TCA-LSTNet 模型,在气温单步预测时,RMSE 和MAE 都优于同类模型,能更好地跟踪数据的非线性动态变化,预测精度更高。在多步预测时,XGBoost-TCA-LSTNet 模型相对于原始LSTNet 模型预测也有一定提升,预测误差总体小于其他模型。
但XGBoost-TCA-LSTNet 模型中将循环层的GRU 替换为BiLSTM,模型运算时间会增加,这在多步预测时表现的更加明显,尤其是遇到大规模数据集时。
未来可考虑对本文方法进行改进,使其能实现并行运算,提高模型的运算速度。
猜你喜欢气温卷积预测无可预测黄河之声(2022年10期)2022-09-27基于FY-3D和FY-4A的气温时空融合成都信息工程大学学报(2022年3期)2022-07-21选修2-2期中考试预测卷(A卷)中学生数理化(高中版.高二数学)(2022年4期)2022-05-25选修2-2期中考试预测卷(B卷)中学生数理化(高中版.高二数学)(2022年4期)2022-05-25基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02深冬气温多变 蔬菜管理要随机应变今日农业(2021年2期)2021-03-19从滤波器理解卷积电子制作(2019年11期)2019-07-04基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20不必预测未来,只需把握现在中学生数理化·八年级物理人教版(2017年11期)2017-04-18与气温成反比的东西小雪花·成长指南(2015年10期)2015-10-23