基于混沌BBO算法的非线性模型参数整定
张滋雨,高岳林+,武宏光
(1.北方民族大学 数学与信息科学学院,宁夏 银川 750021;
2.北方民族大学 宁夏智能信息与大数据处理重点实验室,宁夏 银川 750021)
生物地理学优化算法(biogeography-based optimization,BBO)[1]在后期的收敛速度非常缓慢,容易陷入局部极小值。为提升算法性能,国内外学者进行了大量研究。例如,文献[2]提出的WRBBO算法在迁移算子中加入更有效的随机尺度差分变异算子以获得全局搜索能力。文献[3]将遗传算法集成到BBO中,得到基于遗传变异的GBBO算法。文献[4]提出了一种基于改进变异算子和CMA-ES的混合生物地理学优化算法(HBBO-CMA),提高了算法对不可分离问题的求解能力。文献[5]设计了混合可变邻域搜索策略作为局部搜索方法,以改善BBO局部搜索能力。文献[6]设计了动态的交叉迁移算子,并引入动态高斯变异算子,增强了BBO的新解开采能力。
针对BBO开发能力弱、后期收敛速度慢、易陷入局部极值等缺点,作者设计了一种嵌入动态迁移算子和混合变异策略的混沌BBO算法(DmHmBBO)。采用Tent映射生成混沌初始种群;
将反向学习机制和差分算子集成到原始BBO迁移算子中,得到基于迭代次数而动态调整的迁移算子,提升了算法向最优解移动速度。为增强算法跳出局部最优解的能力,将高斯变异算子和柯西变异算子进行“凸组合”,得到混合变异算子。在验证DmHmBBO算法的优越性和先进性后,将改进算法应用于非线性Richards模型的参数整定,对谷氨酸菌体生长浓度进行预测。实验结果表明,DmHmBBO算法对Richards模型的参数整定有较好的适用性和表现力。
原始BBO算法在求解问题时,表现好的个体被看作是栖息地适宜度指数(habitat suitability index,HSI)高的岛屿。HSI高的岛屿容易向HSI低的岛屿迁移物种,从而改善栖息地的各适宜度指数变量(suitability index variables,SIVs)。BBO模拟这一过程,寻找问题最优解。主要过程包括以下3步。
1.1 初始化
标准生物地理学优化算法的初始化步骤包含两部分内容:初始化参数与初始化种群。初始化参数是设置最大迁入率I、最大迁出率E、最大物种数Smax以及最大变异率mmax。初始化种群是随机产生搜索范围内的NP个候选个体
xi(k)=lk+rand(0,1)·(uk-lk)
(1)
其中,i∈{1,2,…,NP},k∈{1,2,…,D}, 而lk和uk是第k维独立变量的下届和上届,rand(0,1) 用来避免取值超界。
1.2 迁 移
BBO算法在进行迁移操作时,首先需要计算出各栖息地xi的物种数量Si。
而物种数量Si基于栖息地的适宜度排名
Si=Smax-i
(2)
在计算出各栖息地的物种数后,可计算出各xi的迁入率λi与迁出率μi[1]。由于复杂迁移率模型的适用性比线性迁移率模型更佳,本文在实现所有BBO算法时,均采用文献[7]中的余弦迁移率模型计算λi与μi
(3)
在迁移时,首先利用迁出率λi选择出待迁入个体xi中将要被替换的第k维变量;
其次利用轮盘赌算法,在剩下的NP-1个个体中,根据迁出率μi随机选择出待迁出的个体xj;
最后将xj的第k维变量复制给xi的第k维变量。
1.3 变 异
BBO采用变异来模拟栖息地发生环境突变的情况[1]。首先根据λi和μi计算出各栖息地xi的物种概率Pi

(4)
个体xi的变异率mi与其Pi成反比[1]。因此,变异率计算公式为
(5)
变异算子具体操作是对栖息地xi的每一维变量随机产生一个(0,1)间随机数,若某维变量的随机数小于变异率mi,则对该维变量按照式(1)随机产生一个范围以内的数替换掉原来变量值。
2.1 基于Tent映射的种群初始化
原始BBO随机初始化种群,这样得到的种群整体质量较低,多样性较差,不具较好的遍历性,容易造成算法早熟。许多学者采用Logistic映射初始化种群,但Logistic映射遍历不均匀,且影响算法收敛速度。从文献[8]可发现Tent映射比Logistic映射更具遍历性,可令种群个体在问题的解空间中更加均匀地分布。基于此,作者在算法设计时,采用Tent映射产生DmHmBBO算法的混沌初始种群。
Tent映射数学表达式如下
(6)
采用Tent映射初始化种群,既能使提高种群遍历性,又能提升种群多样性。具体步骤为:

(7)
2.2 动态迁移算子
首先,将反向学习策略集成到迁移操作中。原始BBO容易选出差的个体进行迁出,导致迁入个体变得更差。为避免这种情况,本文对待迁出栖息地xj的迁出率μj设定阈值τ, 当轮盘赌选择出的待迁出栖息地xj的迁出率μj小于阈值τ时,对待迁入栖息地xi采用反向学习机制进行迁入。由于文献[9]证明了拟反射反向个体有更大概率接近最优解,因此采用拟反射反向进行迁移
(8)
其次,利用凸迁移代替原始BBO的直接迁移模式。当待迁出栖息地xj的迁出率μj大于阈值τ时,对待迁入栖息地xi进行基于迭代次数的凸迁移
(9)
其中,g是当前迭代次数,MaxIt是算法的最大迭代次数,xb是第g代种群中的最优个体。式(9)的好处是好的个体因为迁移而退化的可能性较小,迁移会保留它们最初的一部分特征,而差的个体会拥有来自好的个体一部分特征。并且式(9)可以使种群快速向最优解移动,提升收敛速度。而基于迭代次数调整迁出栖息地特征与最优个体特征的权重,可以有效平衡种群在不同进化时期的迁移压力。在进化前期,种群整体质量较低,式(9)可使种群快速向最优解移动,提升种群质量;
在进化后期,种群整体已经靠近最优解,式(9)可以让较优解也具有一定生存能力,避免整个解集陷入局部最优解中,可帮助算法提高收敛精度。
最后,将基于局部最优个体的差分算子融入到迁移操作中,增强算法的搜索能力。具体操作是当个体xi在某一维变量上所产生随机数大于λi时,仍然要对该维变量进行迁移。随机选择4个种群个体:xr1,xr2,xr3,xx4, 其中,r1≠r2≠r3≠r4≠i。
利用式(10)进行迁移
xi(k)=xbr1-r4+F·(xr1(k)-xr2(k)+xr3(k)-xr4(k))
(10)
其中,xbr1-r4是4个随机个体中的最优个体,F是缩放因子。使用局部最优个体进行差分计算可以防止算法陷入局部最优值,避免种群多样性随迭代次数急剧下降。此外,局部差分算子可以提高算法的局部搜索能力,特别是在后期迭代时,种群可以在最优解域进行局部搜索,有效提高算法收敛精度。算法1给出了DmHmBBO的迁移操作计算流程。
算法1:DmHmBBO迁移算子计算流程
(1) for 每一个xi
(2) for 每一维变量k
(3) if rand(0,1)<λi
(4) 利用轮盘赌选择待迁出个体xj
(5) ifμj<τ
(6) 利用式(8)进行迁移
(7) else
(8) 利用式(9)进行迁移
(9) end if
(10) else
(11) if rand(0,1)<0.5
(12) 利用式(10)进行迁移
(13) end if
(14) end if
(15) end for
(16) end for
2.3 混合变异算子
原始BBO采用随机变异增加新个体,很可能会使HSI较高的栖息地遭到破坏,发生“反作用”[1]。改进时,比较广泛的是利用高斯变异或柯西变异进行修正[10,11]。但高斯分布随机数搜索范围较小,不能有效帮助算法跳出局部最优;
而柯西分布随机数搜索范围较大,在进化后期不易于算法搜寻最优值,提升收敛精度。为平衡两种改进策略对变异算子的影响,本文提出了一种混合变异算子,将高斯变异算子与柯西变异算子进行基于迭代次数的凸组合,用式(11)作为变异算子

(11)
其中,N(0,1) 是0均值单位方差的高斯分布随机数,C(0,1) 是0均值单位方差的柯西分布随机数。在进化前期,柯西变异权重较大,可以使算法在进化前期进行大范围的搜索,寻找适宜度较高的个体;
进化后期,高斯变异权重较大,可帮助算法在最优值附近进行小范围搜索,提升收敛精度。
2.4 DmHmBBO计算流程
本文在算法改进上,还加入了精英策略,保留上一代中最优的两个个体,替换掉下一代中最差的两个个体,进入到再下一代的初始种群中。算法2给出了DmHmBBO算法的计算流程,由于个体的迁入率、迁出率和变异率都是基于排名的,所以将它们的计算步骤移至迭代以外。
算法2:DmHmBBO计算流程
(1) 初始化参数:I,E,Smax,mmax,τ
(2) 计算各xi的HSI并排序
(3) 按照式(1)初始化种群
(4) 按照式(2)计算物种数量Si
(5) 按照式(3)计算迁入率λi和迁出率μi
(6) 根据式(4)、 式(5)计算变异率
(7) while(不满足终止条件)
(8) 根据算法2进行迁移操作
(9) for 每一个xi
(10) for 每一维变量k
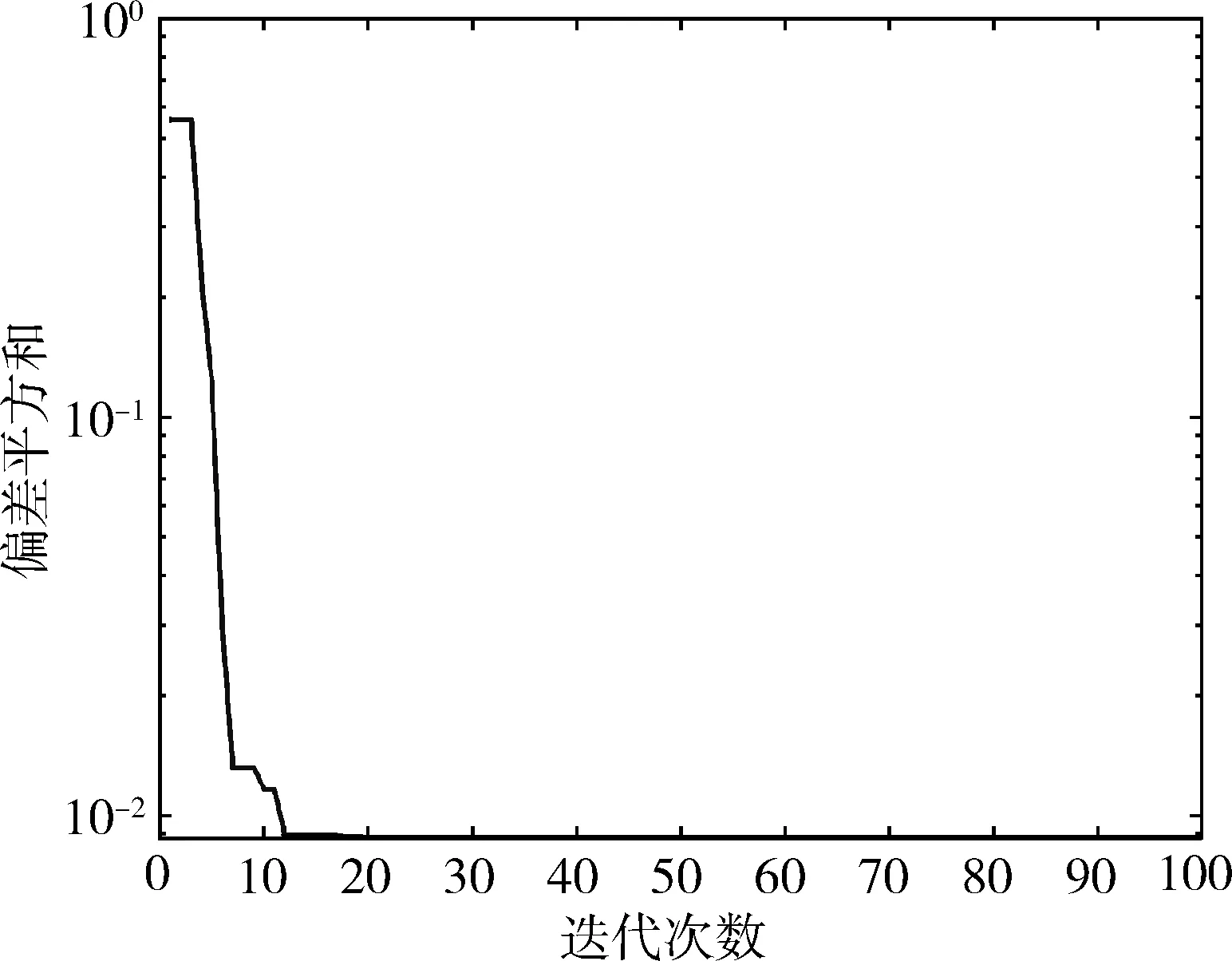
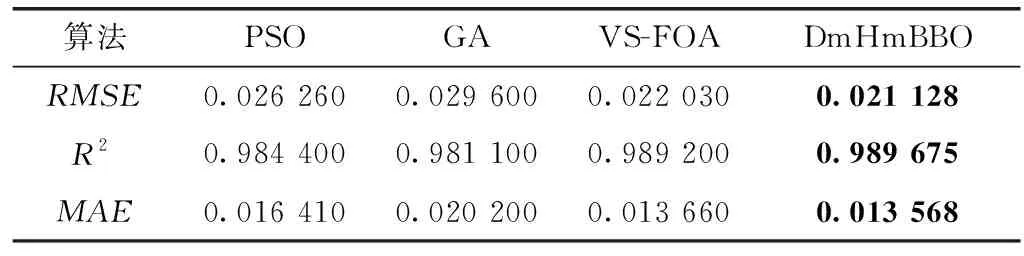
(11) ifmi (12) 利用式(11)进行变异操作 (13) end if (14) end for (15) end for (16) 实施精英策略,重新排序 (17) end 本文采用Markov模型来证明DmHmBBO的算法收敛性。需进行以下说明:①本文所提出的DmHmBBO算法是基于实数编码的,即针对于连续变量提出,所以在证明全局收敛性时,算法的搜索空间是一个连续状态空间。②本文所改进的生物地理学优化算法由选择、迁移和变异等步骤组成,与最大迭代次数无关,并且算法的种群规模固定。因此,可认为DmHmBBO的寻优过程满足有限齐次Markov模型。 定理1 可归约随机矩阵稳定性定理[12]。 n阶矩阵Q是一个可归约矩阵,如果Q可以通过相同的行变换和列变换得到 (12) 其中,C是一个m(m≤n) 阶本原矩阵,而R和T为n-m阶的非零矩阵。如果 (13) 则矩阵Q∞是一个稳定的随机矩阵,并且Q∞=1′Q∞,Q∞=Q0·Q∞唯一确定,且与初始分布无关[12]。 若Q∞是一个稳定的随机矩阵,则Q∞满足条件 (14) 将DmHmBBO种群随机均分为k个子集,则迭代次数为g时,种群可表示为:X(g)={x1(g),x2(g),…,xk(g)}。 根据上述说明可知,对于子种群xi(g),i=1,2,…,k, 可等价于有限次Markov链上的一个状态,用pi(g) 表示处于xi(g) 的概率。则从状态xi(g) 转移到状态xj(g) 的概率,可用pij表示 (15) 由此,可知基于DmHmBBO算法的Markov链的状态转移矩阵P是一个下三角矩阵 (16) 令 (17) S2=(p21,p31,…,pk1)T (18) 则 (19) 根据式(15)~式(18)可知,S1,S2均为非零矩阵。Markov转移矩阵的每一行概率之和为1[12],则p11=1,即p11为1阶本原矩阵。因此,Markov状态转移矩阵P满足定理1的条件要求,故P为可归约随机矩阵。 所以,下式成立 (20) (21) (22) 其中,fitness(g) 为子种群xi(g) 的最优适应度值,f(*) 为全局最优值,P(·) 就表示算法第g代的最优值收敛到全局最优值的概率。由式(22)可知,本文所提出的DmHmBBO算法在经过若干次迭代后一定能收敛到全局最优值,算法具有全局收敛性,证毕。 为验证DmHmBBO的可靠性和先进性,本文进行了一系列仿真对比实验。除原始BBO外,本文还选取DEBBO[13]、HSBBO[14]、PSOBBO[15]、NFBBO[16]、GBBO[3]、DCGBBO[6]等6种改进BBO算法进行比较,以充分验证本文算法的有效性。目前,算法的测试函数主要来源于进化算法大会(congress on evolutionary computation,CEC),应用广泛且较新的是CEC2017[17]、CEC2019[18]以及CEC2020[19],本文总结选取了17个不同类型的测试函数进行仿真,具体信息见表1。 表1 测试函数 其中,f1-f5为单峰函数,用来测试算法收敛速度快慢; 为体现实验的公平性和科学性,8种对比算法的部分参数初始化如下:种群规模NP=50; 此外,在DEBBO中,缩放因子F=rand(0.1,1); 本组实验旨在比较8种算法在17个测试函数上的寻优能力与收敛精度。为避免偶然性,各算法在每个测试函数上独立运行51次。通过计算8种算法在17个函数上独立运行51次后所求得的51个全局最优值的均值和标准差来进行Friedman检验,以比较和研究8种算法的收敛性能。 设置每个测试函数的最大评价次数(MNFE),设置函数f1-f11的MNFE=6000; 从表2可以看出,DmHmBBO在12个测试函数上得到的均值和标准差都优于其它对比算法。而原始BBO在17个测试函数上的结果均没有DmHmBBO理想,可见本文算法有效地提升了原始算法的收敛精度和寻优能力,使算法性能得到极大改善。对比算法DEBBO、HSBBO和DCGBBO仅在1个测试函数上表现出优于DmHmBBO的性能,NFBBO在2个测试函数的寻优结果与DmHmBBO相同,展现出相近的性能,在1个测试函数上的寻优结果优于DmHmBBO。而PSOBBO与GBBO在17个函数上的性能均劣于本文DmHmBBO算法。此外,根据表2还可知,DmHmBBO在单峰函数上的收敛效果非常理想,在f1-f5都精确或高精度地收敛到全局最优值,比其它7种对比算法收敛结果高出至少20个指数级。而在多峰函数f9,f12-f14,f17上,DmHmBBO都精确地寻找到了理论最优值,并且在f12,f17上标准差为零,说明本文算法稳定性强,能够成功地跳出局部最优解。虽然在f7,f10,f11上收敛结果的均值和标准差在8种对比算法中不是最优,但其数值结果也非常接近,其它算法并没有展现出明显的优势。 表2 Friedman检验结果 表2(续) 根据Friedman检验结果,在表2中计算出了8种对比算法的平均排名。显然,本文所提出的DmHmBBO算法获得了第1名,超过了其它7种对比算法,而其后依次是DEBBO、NFBBO、HSBBO、PSOBBO、DCGBBO、GBBO、BBO。从17个测试函数中获得第1名的情况看,DmHmBBO获得12次第1,其次是NFBBO,获得3次,DEBBO、HSBBO、DCGBBO各获得1次,而BBO、PSOBBO、GBBO获得0次。因此,DmHmBBO在8种对比算法中,寻优能力更强,收敛精度更高,具有更好的全局优化性能。 本组实验用收敛情况图来比较8种算法在不同测试函数上的收敛情况。设置最大进化代数MaxIt=1000,各算法在每个测试函数上独立运行51次,取寻优结果最好的一次作为收敛结果,作出8种算法在不同测试函数上的收敛情况图。由于文章篇幅限制,筛选出具有代表性的8个测试函数的收敛情况图进行分析。如图1所示,给出了8种对比算法在单峰函数f1-f4,多峰函数f6-f9上的收敛情况。 从图1可观察出,本文所提出的DmHmBBO算法在单峰函数f1-f3上收敛速度明显优于其它算法,收敛精度在随着迭代次数而不断提高。在单峰函数f4和多峰函数f8,f9上,DmHmBBO收敛到最优解所用的迭代次数比另外7种对比算法少了至少600次。此外,DmHmBBO算法在这些函数上没有像其余进化算法一样出现陷入局部最优的情况,而是从进化伊始就向全局最优值方向快速收敛。此外,NFBBO在函数f8上始终无法跳出局部最优,算法不收敛,由此可知NFBBO并不满足全局收敛性证明。在f6和f7上,8种对比算法都在进化初期陷入了局部最优值,但在种群进化中后期,DmHmBBO有效地跳出了局部最优值,并快速地向全局最优解收敛。综上所述,DmHmBBO算法在8种对比算法中,收敛精度最高,收敛速度最快,整体性能最优,能有效跳出局部最优解,算法具备有效性和先进性。 图1 8种算法在不同测试函数上的收敛情况 简言之,Richards模型可理解为是一个非线性的回归方程,广泛被应用于预测。Richards模型通过控制离散时间变量t来预测和描述生物菌体的生长过程,因此常用来预测一些生物菌体的生长过程情况。其数学表达式为 (23) 式中:t为离散时间取值,yt代表t时刻的生物菌体的生长浓度值。而α表示菌体生长浓度的最大值,β表示菌体生长浓度的初始值,γ表示菌体的生长速度,δ代表菌体生长曲线的形状。对Richards模型进行参数整定的任务就是估计式(23)中参数α、β、γ和δ的值。 以谷氨酸菌体为例,利用本文提出的DmHmBBO算法估计其Richards模型参数,预测出谷氨酸菌体的生长过程。其中,算法的每一个栖息地代表一组参数估计值,即每个个体有4个独立变量,分别代表参数α、β、γ和δ。非线性回归模型参数整定往往是用一组实际观测值估计出各个参数值,本文在进行Richards模型参数整定时,其谷氨酸菌体生长浓度观测数据来自于文献[22]。由于在预测菌体生长过程时,常用偏差平方和评价预测值与观测值之间的误差[21],因此DmHmBBO的适应度函数采用偏差平方和表示 (24) 函数Fitness值越小,表明误差越小,预测值更接近观测值,即参数估计值越准确。使用DmHmBBO算法对Richards模型参数进行寻优,估计出的最优参数取值分别为:α=0.8978,β=5.5796,γ=0.6619,δ=3.7048。得到对应的最小偏差平方和为0.008 927 5,比文献[22]中的最优值0.0114和文献[20]中的最优值0.009 091 1均更小,说明利用DmHmBBO算法得到的预测值更接近于观测值,参数估计值比同类文献更准确。同时,图2给出了利用本文算法得到的谷氨酸菌体生长浓度曲线。仔细观察可以发现,随着时间t的增长,谷氨酸菌落的生长浓度预测曲线与实际观测值之间的误差逐渐越小,在t=10 h时,曲线和观测值已基本重合,说明了Richards模型通过DmHmBBO算法得到的结果较可靠,效果良好。图3给出了DmHmBBO算法在进行Richards模型参数估计时的偏差平方和变化曲线。从图3种可以看出,DmHmBBO算法收敛到最优值0.008 927 5只用了20次不到的迭代次数,而文献[22]收敛到最优值0.0114用了近1000次迭代才达到稳定。说明DmHmBBO算法用更少的迭代次数和计算代价收敛到了更精确的最优值,比同类文献中的算法更具有效性和先进性。 图2 谷氨酸菌体生长过程拟合曲线 图3 偏差平方和变化曲线 本文为进一步充分说明DmHmBBO在Richards模型参数整定中的适用性,将DmHmBBO与其它群智能进化算法进行预测结果对比,选取了粒子群算法(PSO)、遗传算法(GA)、改进的果蝇算法(VS-FOA)作为对比算法。表3展示了4种对比算法计算得到的谷氨酸菌体生长浓度预测结果与实际观测值之间的比较结果。表3中,实际观测值和对比算法的预测数据均来自文献[22]。 表3给出了谷氨酸菌体生长浓度观测值与各算法预测值,但并不能从表中直观地判别出各算法预测效果的优良。为便于和同类文献进行数据比较,本文选用均方根误差(RMSE)、决定系数(R2)以及绝对误差均值(MAE)作为评价指标,判断各对比算法在谷氨酸菌体生长浓度预测上的准确性与有效性。 表3 谷氨酸菌体生长浓度观测值与各算法预测值 均方根误差(RMSE) (25) 决定系数(R2) (26) 绝对误差均值(MAE) (27) 表4 各对比算法的不同指标值 由表4可知,本文所提出的DmHmBBO算法得到的均方根误差(RMSE)、决定系数(R2)以及绝对误差均值(MAE)均比另外3种对比算法更优,说明其预测精度、拟合优度和预测质量都比另外3种算法更好。因此,采用DmHmBBO进行Richards模型参数整定以预测菌体的生长过程,比同类文献中的算法更具有效性和先进性。DmHmBBO为Richards模型参数整定的方法提供了参考,是一种值得采纳和推广的算法。 本文为进一步改进标准BBO算法的收敛性能,在原有进化机制的基础上,设计了一种性能先进的生物地理学优化算法变体,并将其命名为DmHmBBO。仿真结果表明,DmHmBBO在8种对比算法中整体性能最优,算法具备先进性。将DmHmBBO应用于谷氨酸菌体生长的Richards模型参数整定,实验结果表明了DmHmBBO比同类文献中的方法更具适用性,为非线性模型的参数估计提供了参考方法。但从仿真实验结果可看出,DmHmBBO在个别测试函数上仍然不能精确地收敛到全局最优解,其算法性能仍可进一步提升。因此,下一步将对DmHmBBO算法进行深入研究,使其适用于更广泛的寻优问题。此外,在今后的工作中,可重点将BBO改进算法应用于谷氨酸菌发酵过程的软测量,实现对发酵过程重要生化参数的预测估计。2.5 DmHmBBO收敛性证明






f6-f17为多峰函数,用来测试算法的全局收敛能力。3.1 参数设置
最大迁入率I=1;
最大迁出率E=1;
最大变异率mmax=0.05(NFBBO中mmax=0.1);
最大物种数Smax=2NP。
交叉率Cr=0.9;
在HSBBO中,记忆考虑率HMCR=0.9,音高调整率PAR=0.1;
在PSOBBO中,个体控制因子c1=0.5,群体控制因子c2=2;
在NFBBO中,领域大小r=[0.15·NP];
在GBBO中,高斯变异率也设为0.05,精英保留个数为2;
在DmHmBBO中,φ=0.5, 阈值τ=0.5, 缩放因子F=rand(0.2,0.6);
精英保留个数也为2。3.2 改进效果研究
函数f12,f13,f15-17的MNFE=400;
f14的MNFE=2000。各算法运行结果见表2,其中加粗数据为8种算法中的最优值。
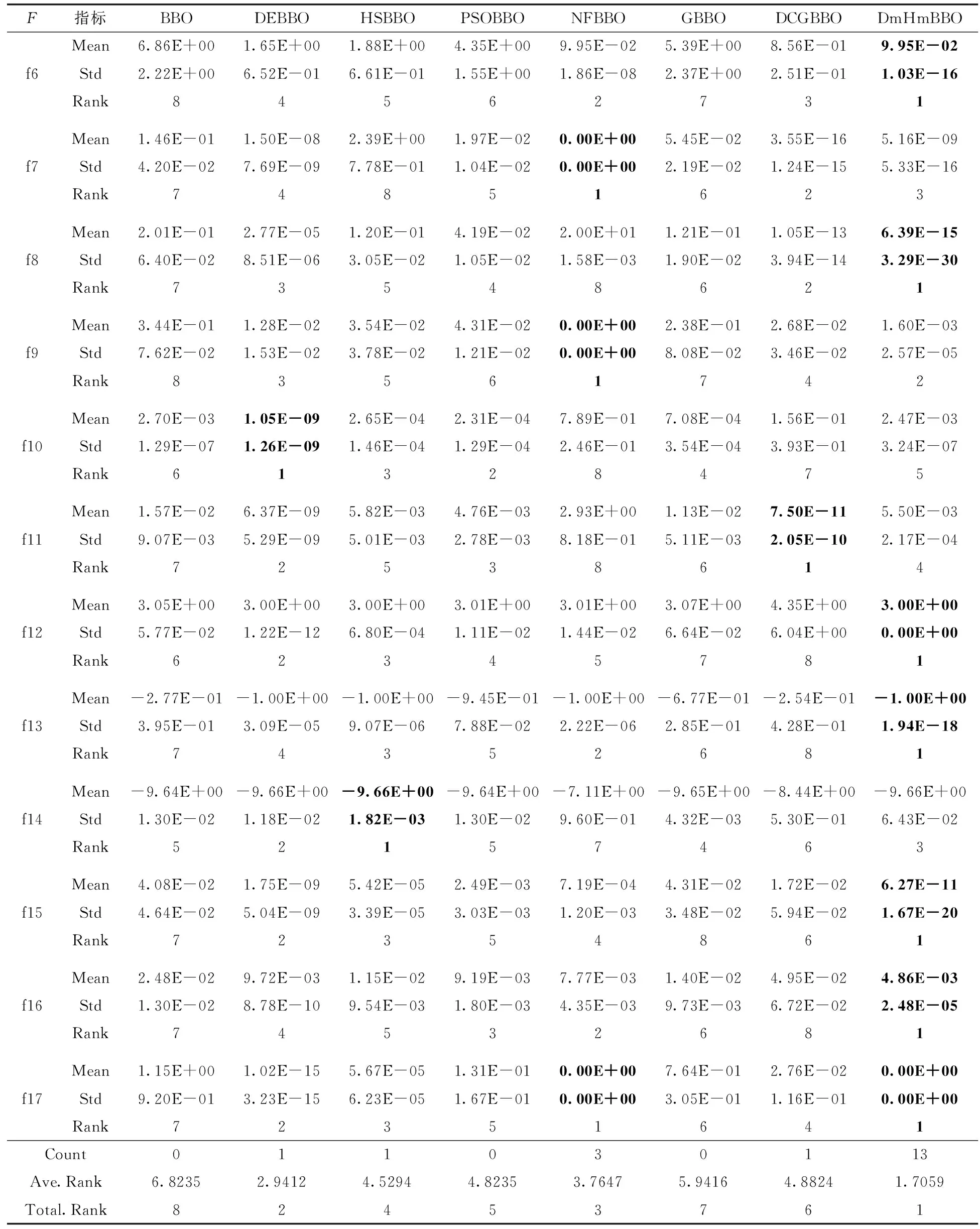
3.3 收敛速度对比




下一篇:历史地理环境与中华文明