基于类别一致性的层次特征选择算法
张智慧 ,林耀进 ,张小清 ,吕 彦
(1.闽南师范大学计算机学院,福建漳州 363000;
2.数据科学与智能应用福建省高等学校重点实验室,福建漳州 363000)
在信息时代,随着数据量的增加,分类问题的规模变得越来越大,给分类算法的效率和准确率带来了严峻挑战[1].例如,在文献[2]中,数百万的图像样本包含数千个类别,每个样本由数百万个特征描述,导致特征空间具有高维性.特征选择是处理分类学习特征维度灾难的重要技术.目前已有大量工作致力于研究利用特征选择解决特征空间高维性问题.Lin 等[3]引入模糊互信息评价多标签学习中的特征重要度,设计相关算法进行特征选择.Peng 等[4]研究如何根据基于相互信息的最大统计依赖性准则来选择好的特征.然而随着分类学习中类别数量的迅速增加,在大规模类别条件下的层次分类学习比传统的平面分类学习面临更加严重的维度灾难问题.因此,对于层次分类的特征选择问题的研究具有重要意义.
近年来,针对层次数据的特征选择方法也越来越受到关注.Freeman 等[5]使用遗传算法优化分类问题,使层次分类器中的基分类器都能获取各自最优特征子集.Grimaudo 等[6]为层次数据集的每一层节点选择的不同特征子集,降低特征维数,提高分类任务的准确性.Zhao 等[7]利用类别相关性关系,将父类和兄弟类之间的关系作为正则化项去评估特征的重要性,为层次树结构的每个节点选择不同的特征子集.但在实际应用中,类别的层次结构不仅表示成一个简单的树结构,通常是一个更广义的有向无环图结构,而上述算法对于有向无环图结构的数据进行特征选择存在一定挑战.
在层次图结构中,一个类别可能同时属于一个或多个父类,因此层次分类学习也可以转化成特殊的多标签或多输出学习[2].在多标签分类特征选择的算法中,标签相似度和特征的权重矩阵有着紧密的联系,并基于此有大量的研究成果.在算法LLSF[8]中,假设任何两个强相关性的类标签比两个不相关或弱相关的类标签共享更多的特征,同时特征的权重系数向量之间有极大相似性.Ren 等[9]提出LDLSF 算法,指出如果两个标签即使是强相关的,它们应该在标签上有相似的输出,而不仅体现在它们的特征权重参数向量上.上述算法虽然能有效解决传统多标记问题中的类别差异问题,但在层次类结构中,两个类别较为相似时,所选特征也会存在较大差异,出现不一致问题,而且子节点比父节点的类别更加具体化.因此,只考虑特征权重相似性选择特征子集是不够的,可以进一步考虑样本的类别一致性来减小所选特征的误差问题.
基于上述思想,本文将分类直接限制在类别的标签输出上,而不是只考虑类别的特征权重系数的相似性,减少不一致性产生的分类误差.利用类别之间的层次结构,充分考虑节点类别与其祖先节点类别、兄弟节点类别之间的关系,获得更准确的特征子集,提高分类精度.因此,本文提出一种基于类别一致性的层次特征选择算法HierASFC(A Hierarchical Feature Selection Algorithm Βased on the Consistency of Categories).首先,基于类别的层次结构,利用递归正则化计算内部每个子类别的相似度,得到一个相似度矩阵,构建特征权重损失函数,学习层次结构中每个子类别的共同特征;
其次,考虑到类别与各自的父类、兄弟类以及区别特征之间的依赖关系,根据输出一致性直接在样本的类别上约束标签的相关性;
最后,对样本特征进行稀疏性学习去除无关特征并在树结构和有向无环图结构的层次数据中进行大量实验,验证该算法的有效性.
综上,本文主要内容安排如下:1)介绍相关基础知识;
2)设计基于类别一致性的层次特征选择算法模型;
3)描述所提出算法的实验结果并进行分析;
4)对本文工作进行总结.
给定X∈Rn×m为一个数据矩阵,Y∈Rm×d是一个类别矩阵,其中n和m分别为样本数和特征的数量,d是类别数量.
特征选择,即选择一个足以充分预测目标类别标签的特征子集.许多特征选择算法将数据矩阵X和类别标签Y的关系表述为一个线性优化问题:

其中:W是特征权重矩阵,L(·)是经验损失函数;
R([W])是对W施加的正则约束项;
λ是一个正常数.
公式(1)的目标是学习得到一个合适的W,使实际的类别矩阵Y与预测的XW之间的差值最小,重构后的矩阵XW能够近似表示原始的数据矩阵X.
2.1 层次分类学习
在层次分类学习任务中,通常分为树结构和有向无环图结构[10],树状结构可以看作是一种特殊的有向无环图结构.首先将数据中样本集X划分为X0,X1,…,XN,同时令Y0,Y1,…,YN表示为对应的标签类别集合,其中,且,dmax是内部节点中类别数目的最大值,类别层次结构的内部节点数为N+1.令表示为内部节点i的权重矩阵,则可构建经验损失项L(Xi,Wi,Yi)学习内部节点i的所有特征,同时考虑到节点间存在共同特征,将其作为正则项包含于Γ(Wi)中,最后为保证特征的稀疏性,加入稀疏性正则项,因此目标函数表述如公式(2)所示:

其中:W0,W1,…,WN分别为根节点和每个中间节点的特征权重矩阵.
2.2 HierASFC算法设计
在层次类别结构中,每个祖先类别和其后代拥有共同特征,同一层次的兄弟类别也会包含各自祖先类别的共同特征.因此,类别的继承性体现了类别之间的一致性,而类别一致的标记之间其特征应拥有更多共同特征.本文对类别的层次结构进行分析得到类别间的相似度矩阵,通过矩阵构造特征权重损失函数去学习每个类别的共同特征.如果类别yi和类别yj越相似,那么二者的特征权重Wi和Wj就越相似,即拥有的共同特征越多.因此,相似度矩阵和分类的一致性需要一起考虑.利用相似度矩阵构造特征损失函数,学习层次结构中各子树类别的输出相似度.输出一致性关系的正则项可以构造如下公式(3):

其中:Cij=1-Sij,Sij表示为各类别yi与其他类别yj相似度,且S∈RN×N.
利用二元关联将层次分类问题转化为基于类别层次结构的多标签学习问题,用余弦相似度计算节点类别的相似度.目标函数(3)可通过控制参数α的大小达到最小化.对于所有节点特征的学习,基于公式(2),本实验采用最小二乘损失作为损失函数并学习l2,1范数加入稀疏学习的正则化项得到最终目标函数,如公式(4)所示:

其中:λ和α为两个非负参数,分别控制着特征的稀疏性和输出一致性的学习.
2.3 模型优化
因为l2,1范数的非光滑性,按照文献[11]中提供的解决方法,对公式(4)中||W||2,1对W的求导计算如公式(5)所示:

对于各个内部节点,根据公式(6)求出关于Wi的导数并设置为0,由此可以求得Wi如公式(7)所示:

计算特征的权值矩阵W=[W0,W1,…,WN],并进行升序排序,选择较大权重值的特征,完成每个节点的特征选择任务.
在本节中,首先介绍在实验中使用的数据集,然后分析参数的敏感性和正则化项的有效性,最后将所提出的算法与一些先进的算法进行比较分析.
3.1 实验数据集
为测试所提出的算法,本文选择10 个数据集,其中6 个是树状结构数据集.具体是蛋白质数据集DD[11]、F194[12],图像数据集VOC[13]、ILSVRC65[14]、SUN[15]和Cifar[7],4 个有向无环图结构的基因数据集,分别是Eisen,Derisi,Cellcycle,Gasch[16].具体信息如表1所示.

表1 数据集描述Tab.1 Data Description
3.2 评价指标和对比算法
在实验中,采用Tree Induced Error(TIE)[17]和Hierarchical-F1 measure(H-F1)[18]两个层次分类评价指标.其中TIE的取值越小说明实验准确率越高,误差越小,而Hierarchical-F1 measure的取值越大则说明算法表现越好.并且引入Friedman检验方法[19]和Βonferroni-Dunn检验方法[20]更加直观地比较各算法的分类性能.

为有效验证HierASFC 算法的性能,本文将该算法与五种层次特征选择算法进行比较.具体信息如下:
1)HierMRMR[6]是一种基于mRMR的层次特征选择方法,为每个子分类器选择不同的特征集;
2)HierFisher是一种由Fisher score[18]改进而来的层次特征选择方法;
3)HierFSNM是一种由FSNM[18]改进而来的层次特征选择方法;
4)Hier-FS[7]是分层特征选择方法,考虑层次中的兄弟节点关系,加入正则化项,提高分类精度;
5)HiRRfam-FS[7]是分层特征选择方法,考虑父子节点关系和兄弟节点关系,为内部每个节点选择不同的特征子集进行分类.
3.3 参数分析
对于Hier-FS 算法的参数依据文献[7]将λ设为10,HiRRfam-FS 算法依据文献[8]将参数α和β设为1.在本实验中,同样采用线性支持向量机(LSVM)作为基分类器,对于HierASFC 算法两个参数λ和α,在树结构和有向无环图结构中通过网格{0.001,0.01,0.1,1,10,100,1 000}搜索最优值.分别列出树结构的VOC数据集与图结构的Eisen数据集,取20%的特征,计算不同参数所得的H-F1值.从图1的结果可以看出当λ=10 时,H-F1 值比较稳定且数值较大,仅次于λ=1;
从图2 的结果可以看出,当λ=1 时在DD 数据集上的H-F1 值较差于λ=10,因此针对树结构的数据集,参数λ设为10 可以得到较好的平均实验效果,参数α设为0.01时的H-F1值也较大;
从图3的结果可以看出,针对有向无环图结构的数据集,λ取100时,H-F1值比较稳定且数值较大,因此参数λ设为100,参数α设为0.01.

图1 VOC数据集的不同参数对应的Hierarchical-F1 measure值Fig.1 Hierarchical-F1 measure values for different parameters on the VOC dataset

图2 DD数据集的参数α对应的Hierarchical-F1 measure值比较Fig.2 Comparison of Hierarchical-F1 measure values for the parameters α on the DD dataset

图3 Eisen数据集的不同参数对应的Hierarchical-F1 measure值Fig.3 Hierarchical-F1 measure values for different parameters on the Eisen dataset
3.4 实验结果与分析
3.4.1 在树结构数据上的性能分析
基于LSVM 分类器,本文在选择相同比例特征所需的时间,TIE 和H-F1(Hierarchical-F1)两个层次分类评价指标将本文算法与对比算法进行比较,实验结果如表2所示,表3和表4中加粗部分表示实验最优结果;
“↑”表示取值越大越好,“↓”表示取值越小越好,每个算法的平均性能用斜体表示.
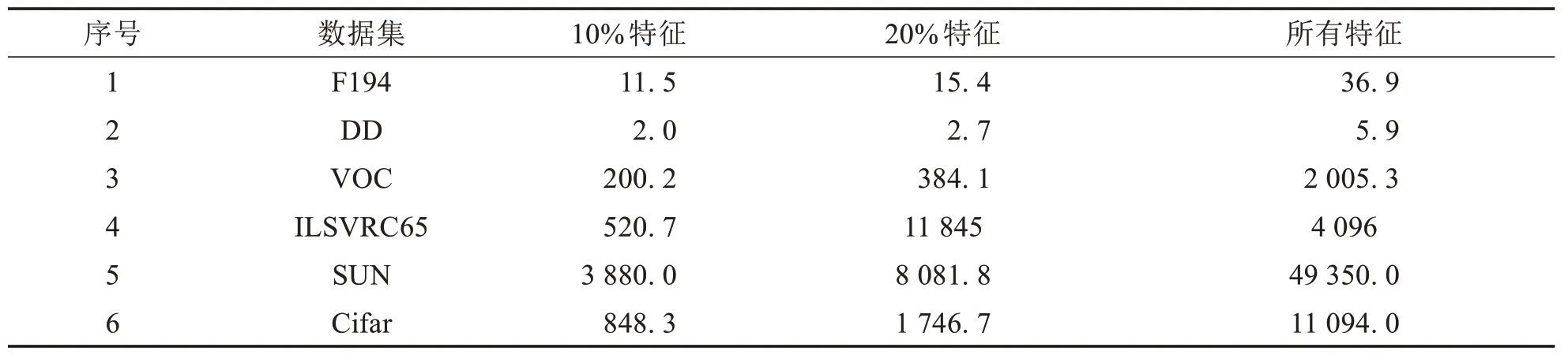
表2 运行时间(s)Tab.2 Running time(s)

表3 6种算法在不同数据集上的TIE归一化结(↓)Tab.3 TIE normalization results of 6 algorithms on different datasets(↓)

表4 6种算法在不同数据集上的H-F1结果(↑)Tab.4 H-F1 results of 6 algorithms on different datasets(↑)
采用Βonferroni-Dunn 检验比较不同算法之间的分类性能差异,计算出平均值序值差别的临界值域,在显著性水平α=0.1 下,有qα=2.326,因此可计算出CD=2.512(k=6,N=6).图4 结果表明,HierASFC算法的H-F1值在统计上明显优于其他算法,具有较好的实验性能.

图4 HierASFC算法与其他算法的性能比较Fig.4 Performance comparison of HierASFC algorithm against the others
3.4.2 在图结构数据上的性能分析
基于LSVM 分类器,对不同层次特征选择算法的分类性能进行评估.结果如图5所示.

图5 图结构的Hierarchical-1值Fig.5 Hierarchical-F1 measure evaluation of graph structure
同样采用Βonferroni-Dunn 检验来准确比较不同算法性能差异,图6 结果表示,在包含有向无环图结构的数据集上,HierASFC算法有更好的稳定性.

图6 HierASFC算法和其他算法在选择不同的特征数量上的性能比较Fig.6 The performance of HierASFC and other algorithms in selecting different number of features
3.4.3 HierASFC的收敛性分析
在实验中,本文设定所有数据集的最大迭代数T=10.从图7中可以看出,10个数据集的目标函数值都是处于单调下降状态,在迭代2次范围内快速下降并趋于收敛;
在不超过10次的迭代次数中达到收敛,这证明HierASFC算法的收敛性较好,极大缩短分类时间,分类效率极大提高.

图7 目标函数的收敛图Fig.7 Convergence diagrams of the objective function
本文提出一种基于层次类别一致性的层次特征选择算法HierASFC.该算法充分利用类别的层次结构所提供的信息,为每个节点选择不同的特征子集,并且能够同时处理具有树结构和有向无环图结构数据集.在实验部分,与5种层次特征选择算法作对比,结果表明本文算法在各个评价指标中均取得较优的结果.
猜你喜欢树结构特征选择类别马克思与列宁的“社会主义”各有什么不同?学习与科普(2019年21期)2019-09-10壮字喃字同形字的三种类别及简要分析民族古籍研究(2018年1期)2018-05-21四维余代数的分类浙江大学学报(理学版)(2017年1期)2017-02-07Kmeans 应用与特征选择电子制作(2017年23期)2017-02-02联合互信息水下目标特征选择算法西北工业大学学报(2015年4期)2016-01-19服务类别新校长(2016年8期)2016-01-10基于特征选择聚类方法的稀疏TSK模糊系统智能系统学报(2015年4期)2015-12-27基于μσ-DWC特征和树结构M-SVM的多维时间序列分类浙江大学学报(工学版)(2015年6期)2015-03-01多类别复合资源的空间匹配浙江大学学报(工学版)(2015年1期)2015-03-01中医类别全科医师培养模式的探讨中国中医药现代远程教育(2014年16期)2014-03-01上一篇:混装炸药的能量与岩石性质匹配研究