面向大规模地震数据并行处理高速可扩展通信技术应用研究
包红林,李 敏,邵志东,张代兰
(中国石油化工股份有限公司石油物探技术研究院,江苏南京 211103)
随着油气勘探向着“两宽一高”的方向发展,通过采集宽频、宽方位、高密度的地震数据提升成像和油气预测精度。高密度地震采集数据规模不断增大,目前原始地震数据炮数高达十几万炮,数据大小高达数TB至数十TB。为满足地震数据成像更精确的目标要求,计算需求巨大的逆时偏移、全波形反演和地震波场正演模拟等数据处理技术被广泛使用,因而大规模地震数据处理面临着海量计算和存储需求的挑战。
面对挑战,地震数据处理技术在方法层面通过优化计算算法来降低计算量或存储需求,基于CPU+GPU异构平台强大计算能力提出逆时偏移算法的CPU/GPU实施对策[1-2]以及有效边界等存储策略[3]大幅降低了波场数据对内存存储的需求,此外,基于超大内存节点提出的波场数据内存存储策略[4]大幅降低了计算量。在软件层面,由于大规模地震数据处理采用地震数据分块并行计算方式,其并行度很高,通过采用高效并行编程方法提升数据并行处理效率。MPI混合并行(MPI+X)[5]模式是目前最常见的一种高效并行编程方法,MPI(Message Passing Interface)是一种基于消息传递的并行编程技术和接口标准,具有程序性能高和扩展性好的特点,在过去及未来相当长一段时间是大规模并行计算的主流编程模式[5],也是实现集群节点间高效并行的编程模式,X是指节点内高效并行编程模式,其中OpenMP并行编程可实现节点内CPU多核高效并行,CUDA并行编程可实现超强算力的GPU众核处理器高效并行[5-6]。在计算资源层面构建的高性能计算集群,由数百台高主频多核CPU节点组成CPU集群(总核数超过万个),或由近百台CPU+GPU异构计算节点组成GPU集群,由于处理技术方法设计对实时通信的需求,集群网络性能直接决定了并行计算性能和均衡扩展能力[5]。大规模地震数据并行处理中,单节点每次计算的结果数据高达数GB[7-8],考虑到结果数据的质量监控及应对计算节点的可靠性问题,通常采用网络实时传输的方法将结果数据传送给主节点或网络存储系统,因而节点数据网络通信需求变大,并行处理通信架构对通信性能要求变得更高,并行处理可能面临通信带宽低、高时延和网络拥塞等性能瓶颈问题,从而成为制约大规模地震数据并行处理计算效率提升的一个重要因素。
为此,本文主要开展并行处理网络架构与技术研究,以解决目前存在的网络性能瓶颈问题。
MPI有多种具体实现版本,地震数据处理系统主要使用了IntelMPI,OpenMPI和MPICH等版本。MPI主要有主从并行和对等并行两种并行模式,由于主从并行模式具有管理自动化、负载动态均衡和节点容错等特点[9-10],可以进一步提升MPI并行计算效率[10],因而被大规模地震数据处理广泛使用。本文主要分析MPI通信框架技术及存在的性能瓶颈问题。
1.1 地震数据处理MPI通信框架技术分析
大规模地震数据处理主从并行模式由一个应用主进程和许多应用从进程组成,运行在集群的一个主节点和若干个计算节点上。应用主进程负责作业任务调度管理,应用从进程负责对主节点分配的不同地震数据集进行数据处理。在主从并行模式中,地震数据管理主要有主进程数据管理和从进程数据管理两种方法。主进程数据管理方法是由主进程统一负责从网络存储系统读取原始地震数据集并对计算节点进行数据分发,同时收集计算节点计算结果并进行网络存储系统数据存储等数据管理,采用这种方法,主进程还可承担从进程计算结果数据汇总计算等工作,实现边收集数据边汇总计算的工作模式,节省了后期单独进行汇总计算的数据存取和计算的时间成本。从进程数据管理方法是从进程根据主节点分配的作业任务各自负责从网络存储系统读取对应原始地震数据集,以及计算结果存储到网络存储系统等数据管理。这两种方法对网络性能需求基本相同:一是计算节点与主节点或网络存储系统间的网络满足大数据量的网络高效传输需求,二是主节点或网络存储系统网卡配置满足其同时与多个计算节点通信时应对大并发流量网络性能需求。因此本文以主进程数据管理方法为例进行分析研究,结果可为从进程数据管理方法借鉴。图1显示了地震数据处理并行计算的主从模式。

图1 地震数据处理并行计算的主从模式示意
MPI通信框架由MPI消息通信接口、网络通信协议和以太网等通信技术组成(图2),MPI消息通信接口提供给并行计算编程直接调用,TCP协议承载MPI消息通信,IP协议实现网络路由,以太网实现网络硬件链路通信和管理。以太网具有传输速度高、低能耗、兼容性好、应用广泛成熟等优势,以太网端口速度已从10GE 提升到100GE,并向400GE端口目标前进[5]。

图2 MPI通信技术框架
随着大规模地震数据处理集群节点数量的快速增长,由大型框架式交换机构建的集中交换拓扑架构因受节点可接入规模的限制,已逐渐演变为如图3所示的由多台小型高性能盒式交换机组成的脊叶交换拓扑架构,面对高达TB规模地震原始数据进行处理所引发的数据网络传输压力,叶交换机提供10GE或25GE(100GE一分四模式)接入端口,满足计算节点接入需求和较大的节点数据网络传输需求。

图3 地震数据处理GPU集群网络拓扑
1.2 地震数据处理MPI通信框架性能问题分析
对大规模地震数据处理MPI通信框架技术的性能监控与分析发现集群节点高速以太网因使用TCP协议存在一些性能问题,以及主从并行模式下存在的主节点或网络存储系统网络性能瓶颈。
高速以太网因使用TCP协议存在网络带宽低、高CPU负载与高时延等性能问题。TCP协议受其诞生时代的限制,存在网络拥塞与网络速度不稳定问题,服务器进行网络通讯时需经内核多层数据拷贝与协议处理(图4a),造成服务器网络传输时延较大、CPU负载较高等问题,在以太网端口升级到10GE后,TCP协议采用的反应式拥塞控制算法,无法胜任流量突发性更强的高速网络传输,并面临网络协议处理的高CPU负载与高时延等性能问题[11]。在如图3所示的GPU集群上运行地震数据处理应用时,通过系统命令监控使用TCP协议的节点25GE网卡带宽使用情况,监控得到网卡最大吞吐量为1.17GB/s,仅为网卡标称带宽的37.4%,因此验证了高速以太网使用TCP协议存在网络吞吐量不高的性能问题,使其不能满足大规模地震数据处理的高网络吞吐量和低时延应用需求。2000年,国际组织IBTA(InfiniBand Trade Association)发布Infiniband(IB)协议[12](图5),给出了一种用于高性能计算集群网络通信标准,IB采用全新硬件和网络协议保障数据传输可靠性,并使用RDMA(Remote Direct Memory Access)[13]技术提供两台服务器用户进程间内存直接存取(图4b),实现系统内核旁路和零拷贝等特性,使服务器网络处理时延降低到1 μs,在高带宽、低延迟与CPU占有率的需求场景下得到广泛应用[14]。但因IB网络相对以太网存在应用不够广泛、生态不够成熟、价格相对较高等问题,在大规模地震数据处理系统中应用较少。
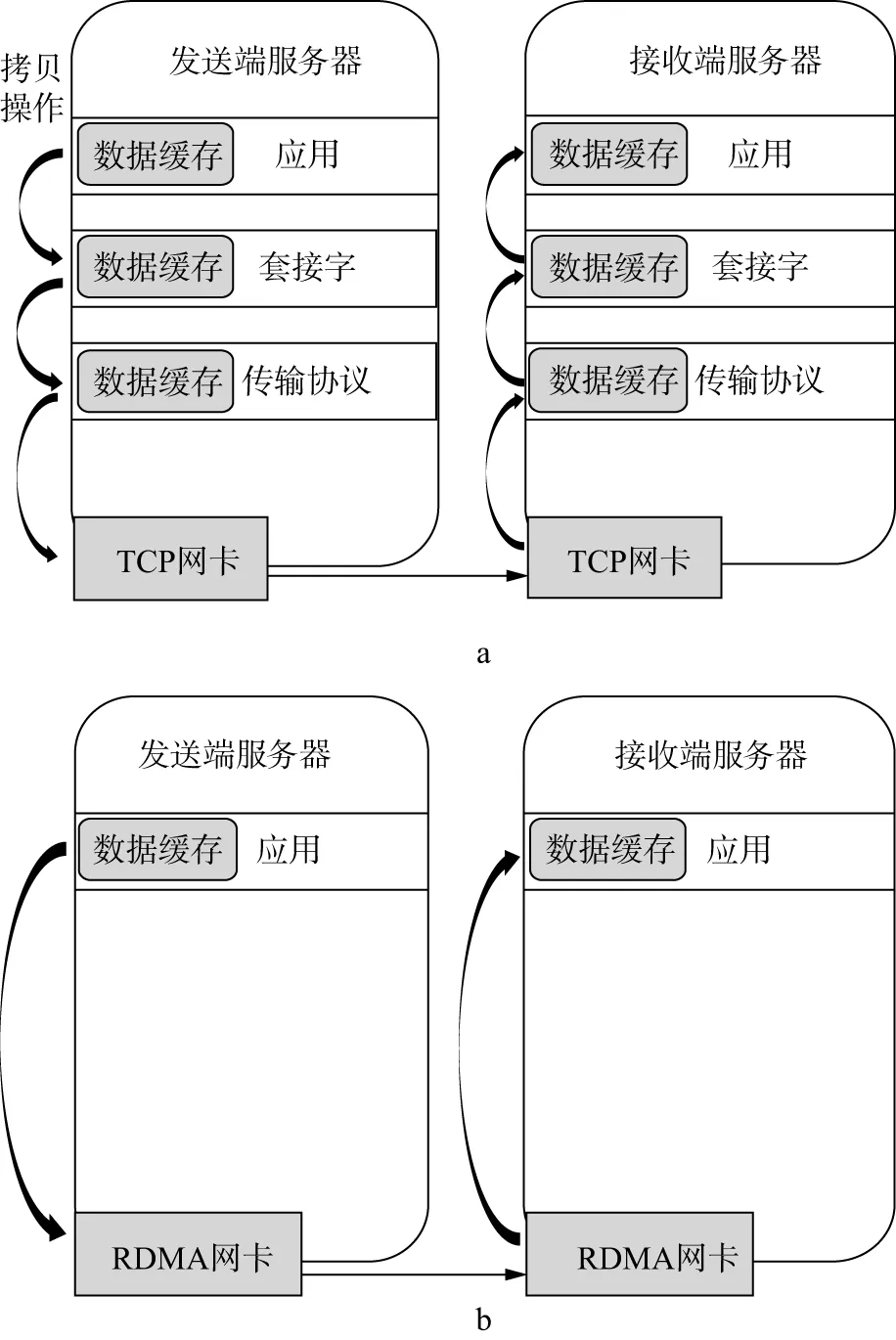
图4 TCP/IP(a)与RDMA(b)处理流程
在地震数据处理主从并行计算中,存在主节点数据网络传输性能瓶颈。在主从并行模式中,由于主节点需要读取原始数据并分发给计算节点,同时,收集从进程计算的结果数据(数据量达GB级别)并存储,因此主节点网卡性能成为主从并行模式下数据网络传输的性能瓶颈之一。这个性能瓶颈在集群网络配置时往往被忽视,主节点网卡配置往往与计算节点相同,例如在GPU集群网络中主节点和计算节点均配置25GE网卡,主节点网卡性能不能满足数据网络传输需求,网络拥塞问题也较严重,集群监控发现,不少计算节点因等待主节点成果数据回收工作的完成而空闲,因而影响了计算节点计算性能的高效使用。
综上所述,因高速网络使用TCP协议存在的网络带宽低、高时延与CPU负载等网络性能问题,以及在主从并行模式下存在的主节点数据网络传输性能瓶颈,成为影响地震数据处理计算效率提升的两个重要因素,随着集群计算节点规模的线性增长,集群计算节点规模可扩展性下降明显。本文在研究分析计算机网络技术发展的基础上,提出了采用RoCE(RDMA over Converged Ethernet)[15]解决TCP协议的网络性能问题,采用100GE网卡解决主节点数据传输性能瓶颈问题,采用UCX(Unified Communication X)提升应用系统可移植性与使用便捷性的软硬件优化设计方案,实现高速可扩展的大规模地震数据处理通信应用方案,有效提升并行处理的计算效率。
采用RoCE协议替代TCP协议,在以太网上实现RDMA技术,大幅提升网络数据传输带宽并降低服务器延时。2010年,IBTA发布了RoCEv1(图5),在以太网链路层上用IB网络层替代了TCP/IP协议,因不支持IP路由,只能在同一子网内通讯,使其应用受到限制。2014年IBTA发布了RoCEv2(图5),用TCP/IP中的UDP/IP替代了RoCEv1中的IB网络层,通过IP实现网络路由,由UDP(User Datagram Protocol)承载RDMA并实现ECMP(Equal-Cost Multipath Routing),为解决UDP没有可靠传输机制问题,利用IEEE 802.1 DCB(Data Center Bridging)标准中PFC(Priority-based Flow Control)和ECN(Explicit Congestion Notification)[16]等技术,构建无损以太网支撑RDMA[14],RoCE网卡只需实现简单传输协议[11],无损RoCE带宽与IB网络的带宽相当,时延比IB略高。由于10GE及以上以太网网卡和交换机基本都支持RoCEv2协议,因此无需更换以太网硬件,通过对网卡和交换机进行相关配置,即可在现有高速以太网上实现RDMA,获得其高吞吐量、低时延和CPU占有率等特性,从而大幅缩短大数据量成果数据的网络传输时间,避免或降低网络数据传输拥塞,更好应对大规模地震数据处理的数据网络传输压力。
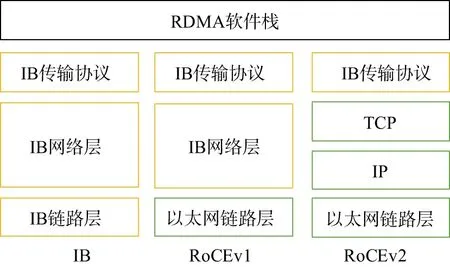
图5 IB和RoCE协议框架
主节点配置高性能网卡并优化集群网络拓扑架构(图6),降低计算节点等待时间,提升计算节点使用效率和集群计算节点规模的可扩展性。高速以太网端口应用方案为:①对于主从并行模式,主节点配置更高性能的100GE网卡,利用其超高性能优势应对主节点一对多通信模式及面临的网络数据传输压力,快速完成与计算节点的网络通信,减少计算节点的等待时间;②根据目前大规模地震数据处理数据网络传输需求,建议计算节点配置25GE网卡,其具有较高性价比,可基本满足应用每次网络传输高达数GB的数据网络传输需求。

图6 CPU计算集群网络拓扑
集群网络拓扑架构优化方案为:①对于计算节点规模不大的GPU集群网络,配置1台64个100GE端口的盒式高性能以太网交换机,就能满足其100个计算节点接入需求,并可实现主从并行模式下主节点与计算节点间的数据网络传输,传输网络路径最短,从而获得更低的网络延时;②对于计算节点规模很大的CPU集群网络,建议采用更高性能的脊、叶交换机,并将主节点直连脊交换机,可使主节点与计算节点间网络路径长度一致,主节点回收计算节点成果数据的网络延迟基本一致,解决了部分计算节点等待时间长的问题。
应用UCX技术提升地震数据处理系统可移植性与使用便捷性。UCX是一个为MPI、SHMEM等高性能并行计算编程开发的开源、统一、标准化通信编程框架。UCX屏蔽底层硬件技术,支持不同网卡、处理器架构和Linux操作系统,以及TCP/IP、IB、RoCE、Shared Memory和Cray/uGNI等基础通讯。UCX在对高性能并行计算编程使用的各种消息传输技术优化基础上,开发了一套高性能、可扩展、易维护的通信库。通过集成UCX通信库,OpenMPI与OpenSHMEM等高性能并行计算可在各种高速网络平台上实现高效通讯,国防科技大学开展了基于天河互连网络的UCX通信框架实现和性能测试[17]。使用MPI+UCX通信模式,地震数据处理系统无需进行程序修改,利用UCX的高性能、高兼容和可扩展的特性,可使应用系统在不同类型的计算资源和高速网络上自适应并高效实现,大大提升应用系统可移植性和使用的便捷性。
由于逆时偏移计算量巨大,如果原始地震数据达到TB级别规模,那么仅成像计算节点成果数据就高达数GB,所以本文以逆时偏移成像为例进行通信框架优化应用方案的应用研究,采用大规模实际生产数据进行应用测试。
3.1 基础平台搭建与网络性能测试
对逆时偏移处理系统使用的以太网交换机和网卡进行技术性能检查。以太网交换机和网卡都支持RoCEv2协议,通过服务器和交换机系统升级,并对网卡与交换机系统进行相关配置,即可实现集群网络RoCE协议。逆时偏移系统使用主从并行模式的OpenMPI,根据通信框架优化应用方案,采用OpenMPI(4.0或以上版本)+UCX通信库,为主节点配置100GE网卡,并直连至脊交换机。
对使用RoCE协议的主节点和计算节点进行点对点的网卡带宽性能实测,测试结果如表1所示,可以看出,使用RoCE协议最大使用带宽相比TCP协议可提高2.6倍以上。在25GE网卡测试基础上,采用OpenMPI测试样例对OpenMPI+UCX进行性能测试,其最大使用带宽可达2.98GB/s,与RoCE(3.06GB/s)测试结果相比下降很小,说明UCX是一个高效的通信库。

表1 TCP与RoCE协议网卡性能实测结果
3.2 应用测试
对分别采用原有通信框架(主节点配置25GE网卡连接到叶交换机、OpenMPI+TCP)和优化通信框架的逆时偏移处理时间进行对比,测试数据选用实际生产中数据量较小的常规数据和数据量很大的大规模数据。
常规数据测试选用9864炮较低密度地震数据,数据量大小为530GB。配置节点数量倍数增长的25个、50个、100个GPU计算节点,分别在两种通信框架上进行逆时偏移处理,获得不同节点规模下逆时偏移处理时间,测试结果如表2所示。由测试结果得到的节点加速比结果如图7所示,可以看出,在原有通信框架上逆时偏移处理随着计算节点数成倍增长,节点加速比低于线性加速比,说明使用TCP协议时,随着计算节点数量成倍增长,主节点配置25GE网卡进行成像结果数据回收时,其网络拥塞问题变得越来越严重;而在优化通信框架上逆时偏移处理随着计算节点数成倍增长,节点加速比高于线性加速比,说明使用RoCE协议及主节点配置100GE网卡,有效解决了主节点成像结果数据回收的网络拥塞问题。使用100个计算节点时,优化通信框架逆时偏移处理时间缩短了1.05h。

表2 两种通信框架常规数据逆时偏移处理的测试结果

图7 优化与原有通信框架节点加速比对比结果
大规模数据测试选用87838炮高密度地震数据,数据量大小为7TB。因高密度地震数据逆时偏移成像处理对计算能力要求很高,故只采用100个GPU计算节点分别进行两种通信框架逆时偏移处理,两种通信框架逆时偏移处理时间测试结果如表3所示,可见,优化通信框架逆时偏移处理时间缩短了40.2h。

表3 两种通信框架大规模数据逆时偏移处理测试结果
对两种通信框架逆时偏移处理时间进行分析,得到使用100个计算节点时优化通信框架逆时偏移处理计算效率提升结果(图8),在本次应用测试中,优化通信框架逆时偏移处理的计算效率提升范围为32.8%~49.9%,说明优化通信框架逆时偏移处理对于不同规模数据的计算效率提升存在差别,主要是由于常规数据成像成果数据相对较小,优化通信框架中主节点收集计算节点成像结果数据时间相对更短,且不存在网络拥塞问题,因此计算效率提升要更高一些。

图8 不同数据规模及通信框架下逆时偏移处理时间与效率提升的对比结果(100个计算节点)
针对大规模地震数据并行处理,采用100GE网卡与RoCE等高速可扩展技术构建的大规模地震数据并行处理通信应用方案,解决了目前并行处理面临的TCP协议效率低以及主节点或网络存储系统网络性能瓶颈等问题,计算节点可快速完成数据通信,提升了大规模地震数据并行处理的计算效率以及大规模集群均衡扩展能力,能够缩短大规模地震数据并行处理时间,并减少计算能源消耗。
随着网络技术发展,超高性能交换芯片和200GE、400GE交换端口等相继推出,将进一步提升集群网络传输带宽。服务器方面,采用将网络接口集成到CPU芯片的计算与网络互连紧耦合架构,将进一步降低网络传输延迟并提升网络传输效率。这些技术可使大规模地震数据并行处理通信应用方案满足规模快速增长的地震数据并行处理应用需求。未来随着光交换技术的发展及其在E级超级计算集群网络中的应用,可以满足巨大规模的地震数据并行处理应用的需求。
猜你喜欢 网卡以太网数据处理 认知诊断缺失数据处理方法的比较:零替换、多重插补与极大似然估计法*心理学报(2022年4期)2022-04-12基于低频功率数据处理的负荷分解方法能源工程(2021年6期)2022-01-06无人机测绘数据处理关键技术及运用建材发展导向(2021年12期)2021-07-22部署Linux虚拟机出现的网络故障网络安全和信息化(2020年3期)2020-04-20Server 2016网卡组合模式网络安全和信息化(2019年1期)2019-02-15基于MATLAB语言的物理实验数据处理探讨电子制作(2017年20期)2017-04-26三大因素驱动创新提速以太网快步迈入“灵活”时代通信产业报(2017年6期)2017-03-27三大因素驱动创新提速 以太网快步迈入“灵活”时代通信产业报(2017年3期)2017-03-24谈实时以太网EtherCAT技术在变电站自动化中的应用电子制作(2017年24期)2017-02-02挑战Killer网卡Realtek网游专用Dragon网卡电脑爱好者(2015年15期)2015-09-10