融媒体视角下多模态词典文本的设计构想

摘 要 随着信息和通信技术的发展以及数字媒体在辞书编纂中的运用,多模态和融媒体词典成为辞书界热议的话题。但从发表的文章来看,它们大多模糊了媒体与模态的关系,所涉词典并不具有真正的多模态特征。文章从纸质辞书的困境与数字化辞书的必然性入手,从三个方面来探讨如何在融媒体框架下设计多模态词典文本,阐释多模态元素的释义功能,包括词典从平面媒体向融媒体的进化、融媒体框架下的媒体与模态的融合、多模态词典文本的特征与数据结构等。
关键词 融媒体 多媒体词典 多模态词典文本 多模态释义
词典与新媒体的结合使词典的查阅终端发生了很大变化,这种词典表象的变化倒逼词典文本结构和释义内容不得不发生改变,因为词典只有多模态化和数据化才能适应融媒体的技术需要,且其改变程度也决定着词典满足数字时代词典用户需求的程度。(章宜华2019)本文从融媒体视角探讨(外语)语文学习词典如何进行模态与媒体的融合,并提出多模态释义构想。
一、 纸质辞书的困境与数字化辞书的必然
词典的核心问题是释义,这是国际辞书界的共识。但释义是一个复杂的问题,尽管词典编者把主要精力都放在释义上,但其问题仍是层出不穷。在纸媒时代,词典学家们为了使释义准确易懂,把使用了几千年,但释义模糊且容易引起循环释义的同义对释逐渐转换成了“解述型”释义,或以括注的形式对释义词进行各种限制,并在学习词典中推行控制性释义词汇(controlled defining vocabulary:2000—3000基本词汇)。释义方式经历了从词汇对释到短语释义(phase definition),从短语释义到句子释义(sentence definition),又从句子释义到情景释义(situational definition)的过程;但循环释义、内涵不彰,或释义庞杂(释义夹杂各种注释)、理解困难,以及注释信息冗余与文化信息欠缺、释义过度与释义不足、概念模糊与用法不清等问题同时存在。为此,词典又增加了文化信息、用法说明和语义辨析等附加内容,百科性词典和学习型词典还引入了插图。
但无论词典学家如何努力,纸质词典的“进化”变得越来越困难。譬如,“牛津”“朗文”等系列学习词典虽然还在不断修订,但也仅是注释方法的微调和注释项目量的变化,难有大的提升,以致用户对纸质词典的兴趣逐年下降。作者在多年前的调查发现,在接受型的语言活动中,大学生中使用电子词典者居多,达52.23%。(章宜华2015)而近些年,随着新媒体终端的普及,纸质词典的使用率已经降至“冰点”。据张恒等(2017)118-120,155调查,经常使用纸质词典的为4%,偶尔使用的占26%,极少使用的占51%,从不使用的有19%之多。而与此相反,91%的学生表示经常使用电子词典,极少或从不使用的只有3%。这些数据基本符合当时辞书市场的现实;事实上,现在基本100%的学生都使用词典App,经常使用纸质词典的人大致占10%。而笔者接触到的词典学硕士生许多都没有纸质学习词典,需要参考时还要到资料室去借。在这种情况下,数字化就成为辞书发展的必然,也正是在2017年前后,我国专业辞书出版社开始加快数字词典的研发。
二、 词典从平面媒体向融媒体的进化
从信息技术角度讲,当代词典的发展要经历从纸质词典到电子化,再到数字化的过程;前者指词典承载方式由物理媒介向电子媒介转化,后者指将词典中的图像、声音、文字等模拟信号转换为数字信号,是信息数据化和网络化的技术保证。从辞书表征的视角讲,词典则由平面媒体向多媒体、多模态和融媒体方向发展,而媒体融合的对象就是词典的多模态表征。
早在20世纪90年代,纸质词典电子化和网络化已经开始。当时,国内市场上出现了一大批光盘词典,如《康普顿交互式百科全书》《IBM智能词典》《微软书架》《韦氏新世界光盘词典》《美国传统有声词典》等,“牛津”“朗文”也先后推出了光盘和网络词典。尽管这些词典大多是纸质版的电子化,体例结构与传统词典并无二致,但有的学者还是捕捉到了多媒体辞书的动向,并认识到多媒体有三个重要特性:用户友好界面、查阅的交互性、信息的多样性。(麦志强1994;夏南强2000)国内在90年代中期也推出了网络词典(如洪恩在线,1996),《汉语大词典》光盘版(1997)等。但进入21世纪后,专业辞书出版社在“触网”方面一直停滞不前,市场上流行的网络词典和词典App大多出自IT公司,《金山词霸》《有道》《海词》《百度百科》等占据了在线词典的主要市场份额。
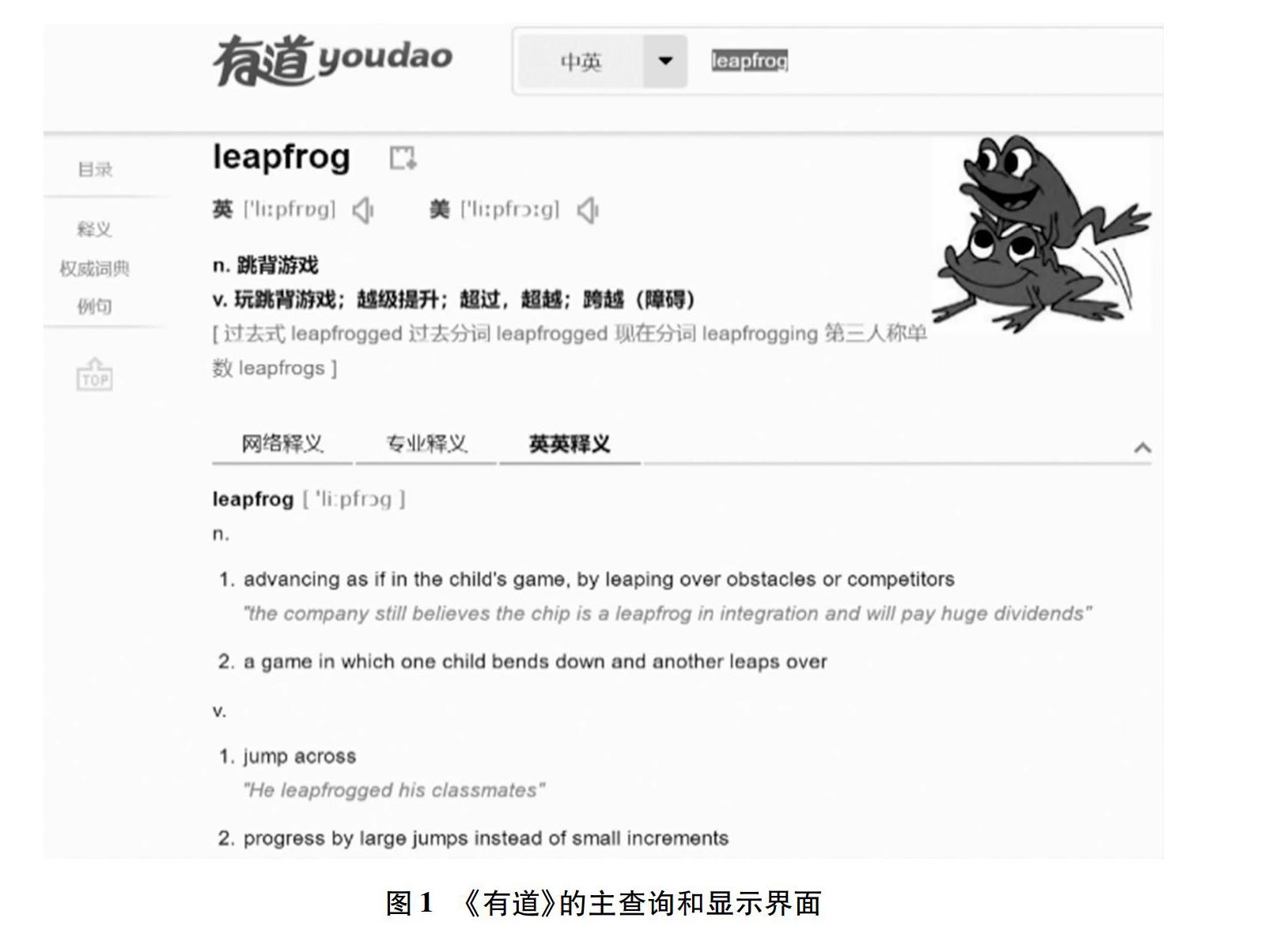
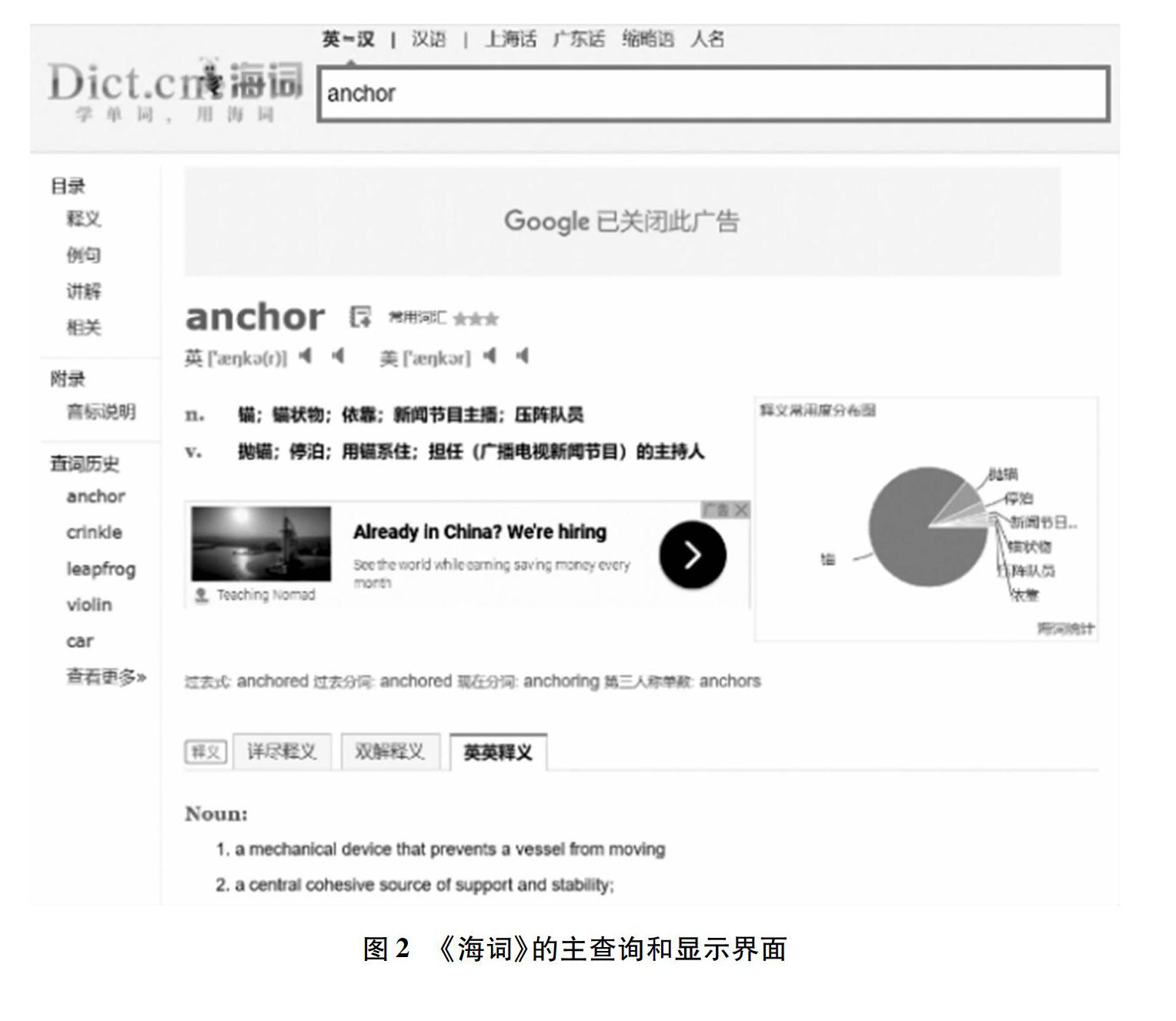
《金山词霸》(以下简称《词霸》)是一款比较经典的电子词典,最大的特点就是全文发音。最初同步发音效果并不理想,2005年引入英语培训品牌视频词库,用户可与教师“面对面”学习,练习听力、发音和语音语调等。2010年后,《词霸》开始整本内置“牛津”和“柯林斯”等品牌词典,但多媒体元素并没有实质性改变,基本不用图形或视频,词典的查询显示仍是平面格式,只是在左边加入一列选择链接(释义、例句、搭配、辨析等)。《有道》和《海词》也都宣称是面向学习者编写的,但在多媒体方面仍是以“读音”为主。《有道》的体例和结构与《词霸》类似,也内置了《柯林斯英汉双解大词典》和《牛津词典》等内容,在少量实物词条(如anchor、animal、car、leapfrog等)中配有图片(参见图1)。《海词》主要是自编内容,没有发现“插图”,但每一词条都提供了“释义常用度分布图”,在“栏目”设置和查询选择方面,可以通过选择“详尽释义”“双语释义”“英英释义”提取和显示不同的释义内容。
总体来讲,上述几种“学习词”主要是信息的堆积,并没有突出的多媒体和多模态特征,且词典信息项的表述方法和质量都不太适合“学习”的需要。例如,《有道》和《海词》都不分义项,把不同的意义混淆在一起,例如:《有道》的“leapfrog v.玩跳背游戏;越级提升;超过,超越;跨越(障碍)”,《海词》的“anchor v. 抛锚;停泊;用锚系住;担任(广播电视新闻节目)的主持人”等。此外,釋义和标注错误时有发生,如“cheerleader(啦啦队员)”被释为“啦啦队长”,“get on ones nerves(让人厌烦)”被释为“令人不安”,及物动词“consolidate(使加强)”后出现了“合计金额”的名词性“对等词”等。《有道》的不少释义是从网上提取的,错误似乎更常见一些,如purple patch本来是“幸运时刻”的意思,却被释为“辞藻华丽的段落”;purchase则释为“……支点;(地产的)年收益;紧握;起重装置”等;boardroom则释为:“会议室;交换场所”;更奇怪的是informations被立为词目[1],释为“information的复数[2]”。这些词典的一大特点是例证丰富,并且还做了分类,但大多是从网上抓取的,未经细致的筛选和区分,也无义项针对性,只是重复的堆积,对学习者的作用有限。
在学界,介绍和研究这类词典的文章也不少,在知网检索到有关《词霸》和《有道》的论文分别为107和20篇,但极少有人把它们作为多媒体词典来研究,批评其编纂质量的却不少。从媒体性质来讲,含有文本、声音和图像等内容的就可以叫作多媒体词典,而上述词典并没有系统、平衡地运用这些媒体,所以其多媒体特征不强。
然而,语言教学界对多媒体和多模态词典的呼声很高,这是因为:1) 语言的自然习得和日常交流都发生在多模态场景;2) 通信技术的发展使人们的阅读习惯发生了改变;3) 多元识读与多模态语境被引入二语教学,对词典提出了新的要求。近十年来,有关多模态词典的研究引起学界重视,波兰学者Lew(2010)提出了多模态词典学(Multimodal Lexicography),党军(2010)也提出了“双语词典多模态化”。但他们的研究混淆了“媒体”与“模态”的概念,把复杂的模态简化为了媒体。之后一些研究(闫美荣2011;罗永胜2012,2015;陈维红2015)大多也是这个路子,有些则从功能语言学的视角来谈词典的图文和语义关系(杨信彰2012;张春燕,陈思一叶2016),有的从界面设置或插图位置来谈多模态电子词典(钱亦斐2016),都没有涉及多模态元素的性质特征和语义表征机制。
那么,模态与媒体之间是什么样的关系?模态的实质特征是什么?多模态元素的语义机制和释义方法是什么呢?我们将在融媒体的框架下来讨论这些问题。
三、 融媒体框架下的媒体与模态的融合
多模态源于系统功能语言学的多模态语篇分析,其主旨在于用各种语言和非语言符号来解释语言的三大元功能:概念功能、人际功能和语篇功能,并指出不同模态可使用不同媒介来的表达。(Kress & van Leeuwen1990/2006;Martinec2005;Royce2007;Matthiessen2007)然而,尽管我们可以从功能的角度来研究词典学(语篇词典学),但词典的语篇毕竟不同于自然语篇,当然也不宜直接用功能语言学中的多模态方法来描述词典中的模态;因为词典组织“语篇”的方法与自然语篇有很大不同。前者是“从具体到抽象”,后者则是“由抽象到具体”的认知过程。另一方面,词典用户是语言“学习者”,查阅词典往往是任务驱动,所以必须要结合词典释义的实际来谈多模态,而不是纯粹套用语篇分析的方法。
(一) 多模态的必要性与可行性
多模态语义表征方法比较适用于二语学习词典,因为成人在学习二语前已经具有比较成熟的母语知识系统,但缺乏或没有二语的语感,离散的(不系统的)词汇知识或孤立的解释往往会受其母语负迁移或目的语规则过度泛化的影响,从而产生中介语偏误。(章宜华2012)从这个角度讲,二语学习者没有一语自然习得的那种语言环境,这就需要我们在词典中营造一种学习者缺乏的自然语境,而多模态释义就是营造这种语境最有效的方法。多元识读理论(New London Group1994,1996)的提出和多模态教学的实施从理论和实践两个方面证明了多模态词典释义的必要性和可行性。多元识读就是对多媒体和多模态信息的解讀能力(Williamson2005),已经被证明是一种二语习得的有效的学习方法(吴玲娟2013;张燕2018;高丽华2018),传统的以读写为主的识读能力在多媒体时代已不够用了(胡壮麟2007)。
实际上,多模态交际方式普遍存在于我们的日常生活,也就是说,我们的任何交际都是多模态的,所以很容易被识读和记忆。然而,传统词典受限于信息媒介的限制,只能是单媒体语境,查阅和理解有一定难度。进入融媒体时代,信息技术和媒体融合技术为多模态在词典中的运用创造了条件,使各种模态可以与数字媒体有机结合起来,能大幅提升词典释义和使用效果。
(二) 多模态表征与承载形式
在词典释义中提供多模态语境或多模态元素有助于二语学习和用户对词典释义的解读。(杨信彰2012;钱亦斐2016)但模态的形成、承载和传输是一个复杂的语言认知和信息处理过程,涉及媒体、多媒体、多模态、融媒体诸多要素。语言认知始于感官(眼、耳、鼻、舌、身),通过光波、声波、嗅觉传感器、味觉传感器和触感传感器获得承载某种信息的图形、声音、气味、口味、感应等意象图式,这就是模态——一种在大脑中形成的心理实体(mental entity)。如果要表达这些模态信息、让他人知晓,就需要借助特定的媒体,包括逻辑媒介和物理媒介,前者包括文字、声音、图像、图形、图表、色彩、结构、动画、视频和音频流等,后者包括纸张、磁盘、光盘、网络、云平台、电波,以及各种终端设备(平板电脑、手机、阅读器等)。从词典学的角度讲,语义模态(词典信息)需要逻辑媒介来承载,而逻辑媒介则需要物理媒体来承载和传播。在融媒框架下,这些元素可以得到有效融合(见图3)。模态因为有媒体承载而具有一定的形式,而媒体则因为承载了模态才具有一定的意义。
(三) 多媒体与多模态的融合
总体来讲,多模态首先是一个“感官模态系统”(sensory modalities)。(顾曰国2015)人们通过这些感官与客观世界互动,并由此产生对应于多个感官的多模态心理意象,然后合成具有语言学意义的模态。具体地讲,多模态是词典用户感知到的词典信息与其指称的实体发生映射而形成的心理意象,并触发相应的心理空间形成“新”“旧”知识的触发和联想,最终形成被释义词的概念图式,以特定的语音、声音、图形、颜色、动作、结构等来表达。这个认知融合过程(化学反应)需有两个条件或“催化剂”:逻辑媒体和物理媒体——媒体是外在形式,模态才是知识内容,两者需要有机融合(参见图3)。
具体地讲,概念图式是抽象的、心理的,它需要用文字、声音、图像或音乐等来表达,通过网络、电视、广播等来传输。这就是模态与媒体融合的逻辑机制。这种融合机制可以有效帮助词典编纂者建立多模态词典释义情景,特别是将来拟真模态和VR技术的运用,它可以模拟一切人类所拥有的感知功能,甚至连嗅觉和味觉也可以参与多模态释义情景的构建,使学习者用户能有身临其境的感觉,使词典的查阅变得“轻松有趣”。
事实上,在多模态环境中,所有的模态都参与意义的构建,(Kress & van Leeuwen1996/2006)因此可以有效提升二语学习者的识读能力。在词典查阅过程中,学习者从所指物→意象→图式概念→文字的感知,要比从文字→意象→图式概念→所指物的感知容易得多。譬如,一张企鹅在北极冰雪中的照片,或其行走姿态、鸣叫声音比任何文字释义的解释都要清楚得多。中国文化特色词,如“算盘”“旗袍”“二胡”“古筝”“秧歌舞”等,对于汉语二语学习者或母语初学者来说,语言解释再配上图像,或集声音、姿态于一体的动态演示或演奏视频,无疑会给用户鲜明、深刻的印象(见图4)。
四、 多模态词典文本的特征与数据结构
释义是词典编纂的核心内容。如果我们认可这种观点,那么我们所做的一切工作(包括语料、信息提取、提炼,以及表述方法和组织形式)都要围绕释义这项核心工作来做。概括地讲,词典释义一是要从语料中提炼出词义的“不变量”(invariant)(Wierzbicka1996),二是要用多模态来表征语义,因为这种形式可以强化词典查阅中的语言输入,增加用户对词典信息的注意力和可理解度(intelligibility)。
(一) 词典释义中的多模态元素
多模态元素指词典释义所涉及的各种模态表征形式,是媒体融合的对象。Bernsen(2008)从信息处理角度来划分模态,共4类67种。Kress(2009,2010)从多元识读的角度把模态概括为能够产生意义的任何符号资源,如文字、图像、颜色、版式、手势、音乐、动漫画等。Lew(2010)从词典编纂的角度分为文字模态、语音频模态和非文字模态,后者又分为:非语言音频、插图、图像、图形和视频片段。国内的研究主要集中在对现有词典所用媒体的分析上(见本文第二节)。从词典释义的角度讲,语义表征所涉及的基本模态有视觉、听觉和(视)触觉等模态元素,但这些基本模态各自又包含若干次模态,加之模态往往是以组合的形式出现,因此词典释义的模态表征还是很丰富的。例如,从视角上讲有文字、符号、动/静态图形、动/静态图像,以及姿势、动作、颜色、结构等;从听觉上讲有语音、静/动态声音、声音符号等;从触觉或视触觉上讲有动/静态触觉、视触觉,包括形态、温度、质感等其他通过肢体和视线接触感知或体验到的事物。
(二) 词典释义中的模态融合
需要指出的是,在多模态词典中,文字释义在较长一段时间内仍然是释义的主要内容,但其他模态不再是文字的附加成分,所有的多模态元素都可以充当被释义词的意义表征。很可能在将来的某一天,现在的图解词典会演化成以非文字模态为主的多模态词典,多模态与VT技术的融合可能慢慢会“削弱”文字释义的作用,成为释义的重要元素。多模态词典的核心内涵就是多种模态在释义中的交互融合,能在用户大脑中产生模态之间的转换,即一种感觉形态刺激引起另一种感觉形态,产生感官的互通和互补。用户在解读和接受释义时调动的感官越多,事物在心智中形成的意象就更趋于真实,解读的效果就更好。此外,用户在查阅中经历了多种媒体——模态的转换和输入,其记忆神经元的刺激就更深刻,其学习兴趣就会更加浓厚。
许多电子词典用了插图和语音等,但它们之间并没有必要的模态融合,故最多只能算作是多媒体词典。严格地讲,文字与图形、图像、色彩等都属于同一种模态,但这些次模态之间的结合与互动、互补比单一的文字更能帮助用户解读语义。例如,由GOOCTO推出的视觉化词库(VISUWORDS),就是用思维导图的方式构成多种次模态的融合,实现了词汇—语义关系的形象化、可视化(见图5)。
这是一种在线图解词典,输入单词便可得到该词的各种意义以及与其关联的其他词类和概念,形成一个可视化词汇—语义关系网络。鼠标指向其中任意节点,便可显示出该节点词的意义。如图6所示,名词borrow有7个义项或有此义的其他词及词类,其中与borrow(动词)/borrower/borrowing等有派生關系;与get/acquired/accept/take等有上下义关系,与lend/loan是反义关系;borrower与recipient/receiver有上下义关系,与lender/loaner是反义关系等。图6中的方框是鼠标指向borrowing/adoptation节点显示出的语义解释。
这种以图形、线条、形状和色彩融合形成的“多模态”词汇—语义网络图,既示出了语词的义项、语义和义项关系,又说明了该词与相关词项间的固有关系,为二语学习者提供了一个系统的学习语境。
(三) 多模态元素的释义功能
1. 文字模态
在融媒体学习词典中,无论是单语和双解释义,还是双语词典的译义仍会将文字作为主要释义形式,但限制释义词汇会使释义的准确性、辨义能力,以及简洁性都受到影响,无法揭示出语词的细微含义;因此,文字与其他模态的结合就显得尤为必要。如对文字难以表达的内容可提供其他模态的支持,如以粗体字、背景色来凸显释义和例句中的核心成分,或与相关词条的释义或多模态信息项链接,用鼠标指向某一句式或搭配可激活相应的义项和例句等。还可以把释义与语料库链接起来,从中调取被释义词更多的真实用例,以帮助用户理解和使用。
2. 语音模态
在纸质词典电子化过程中,语音使用比较广泛,由初期的词头发音发展到全句朗读和视频朗读。手持式电子词典还设置了一些“听力练习”“跟读练习”等动态语音功能,但未做好互动融合。在融媒体词典中,语音模态表征的对象为词目词、例句和人人/机交互。在信息互动方面,词典可以语音领读,用户可以跟读并录音,做对比分析、纠正发音。语音还可与视觉模态相结合,在朗读例句时相应的阅读部分有图标或色彩跟随移动,并与译文关联,让听觉和视觉模态共同作用于用户的信息解读,以“语音—形态”的融合加深记忆。
3. 声音模态
指语言以外的声音,是某些词的主要语义特征之一,如动物、昆虫、鸟类、禽类、乐器、音乐、音频信号、警示声信号,机器和仪器的声音,以及其他人造物声音。听觉模态与视觉模态融合形成视频,可以表征语义,如“虎啸”“狮吼”“海豚音”等用文字难以描述,若配上“图像+声音”的视频片段会给用户深刻印象。像“琵琶、扬琴、古筝、马头琴”等乐器,“西皮、二黄、慢板、快板”等京剧唱腔,“火车鸣笛(起动、停车、进站等信号)”,像cackle、clank、clink、buzz等拟声词采用多模态融合释义,不单是文字释义的重复,更是认知的深化。
4. 图形模态
指各种非语言符号以及颜色和结构等。视觉模态之于文字,如画龙点睛,胜过千言万语。语言伴生符(字体、字号、粗细、颜色)与文字直观融合,已在学习词典中广泛使用,体态符号(动作、手势、表情、视线、姿态等)往往以(连续)图片、动图、动画和视频片段来表示,动作性符号、声音符号、图形/图像符号等是真实的模拟,而目视符号(地图、标识等)则是概括的约定。须指出的是,图形和图像的功能和释义效果是不一样的,如鸟的照片反映的是其“原型”,但它也源自范畴成员,包括了很多个性细节(属于意象),无法涵盖其他范畴示例的特点;而线条画则是众多鸟实例的抽象(属于图式),其释义概括性更强(见图7)。
在视觉模态的组织中,可运用范畴化和格式塔心理学的方法,借助部分与整体关系来凸显个体特征。例如,《牛津高阶英汉双解词典》(光盘版)往往把同一范畴的插图整合在一起,点击图中的单词便可弹出其释义窗口(见图8)。这样,通过同类比较、总体把握与个别凸显,可以提高用户解读的效果。但由于该词典没有真正从模态融合的角度考虑,文字与插图相互独立,检索不到flower、bud、stalk等词条与这个图组的关联。
5. 触觉模态
指静/动态物理接触感和视接触發生的感应模态。前者主要反映在词典使用终端图形用户界面(GUI)上,通过鼠标、手指和声音来触发词典的查询功能和词汇—语义之间的链接,后者通过视线感知查询显示的内容,包括物体状态、温度、质感等内容。词典文本中所有的模态信息都在这个界面上交互和/或融合。因此,图形用户界面的构建是词典发挥多模态效用的关键。
(四) 融媒体词典的特征和数据结构
如果要真正做到媒体融合,多模态词典就无法像纸质词典那样有明确、固定的文本结构,因为各种模态的编码、存储和表述方式不一样,一个词条的信息内容复杂且信息量巨大,利用平面直观的方式排列是不现实的。而现在的电子词典只是载体发生了变化,其信息组织和呈现仍然是平面结构,因此不能算作多模态词典。下面我们谈谈基于融媒体技术的多模态词典的特征和数据结构。
1. 词典的使用环境基础
信息化时代,词典用户全民化、使用需求标签化、信息查阅碎片化、查阅路径网络化,用户使用习惯的改变决定了词典使用终端的电子化和多样化,以便在任何时候、任何地方、用任何数据终端都能查阅,且能快速、准确地获得任何领域的内容,满足其不同语言活动的需要。词典使用终端不再是固定的,而是因时、因地、因人而异的,其载体可以是纸媒,也可以是电脑、平板电脑、手机或电子穿戴用品。
2. 词典文本构成要素
数字化时代,人们对信息的需求个性化、选择丰富化。用户这种需求的改变决定了词典收词和文本要素的改变,即收词要规模化、综合化、系统化,词典释义成分多模态化,词典信息的组织数据化。各种模态信息须高度融合,能跨媒体或全媒体传播。转化的核心就是词典释义元素——由单纯是文字向多模态转向,语音、声音、图形、图像、色彩和感应等都作为重要表征形式参与词目词的释义。
3. 词典文本结构框架
融媒体时代,词典文本元素和使用终端的多元化决定了词典信息要集群化、融合化、生态化。集群化指要模糊类型概念,逐步把各类词典集合在一起,为所有用户提供个性化使用体验;融合化指编纂主体融合、词典资源融合、词典类型融合、多模态—多媒体融合;生态化指词典各类用户可以根据自己的需求准确、快速地获取所需信息(不需要通篇浏览寻找),或与词典文本或编者进行互动,模态与媒体、用户与编者相互作用,形成相互依存、相互促进的生态环境。
根据上述特征,融媒体词典是运用专门的工具,按多模态—多媒体融合和个性化查阅需求对词典进行数据化处理。具体编纂结构有以下几个特征:
1) 词典编纂不再是以词头特定顺序组织编写,而是借助计算机辅助编纂系统中的范畴化分类模型来构建任务分配体系,根据语词的形态、词族、概念、主题、语用,以及属性、行为、事件和事物等范畴来组织宏观结构,运用任务管理平台按既定分类进行编纂,以及进度和质量监控。
2) 词典的基本编写单位不再是完整的词条,而是词典微观信息项中的某一项或几项数据内容,如形态变化、语音、语法和句法注释,义项确立、释义、配例及例句翻译,各种附加信息、模态信息等。一个编者可负责若干字母,甚至整部词典全部词条的某项或多项内容。文字和符号、语音和声音、图形和图像,以及动画和视频片段等构成不同的元数据,以便融合处理、组织成多模态语义表征。
3) 词典信息不再是有限的、类型分明的供给,而是模糊类型、全面提供多模态信息,包括语言属性、语域属性、专业属性及其显示度,尽力满足各层次用户或系统化,或碎片化的信息需求;从视觉、听觉、触觉的角度建立文字与声音、文字与图形、用户与文字/图形/声音、用户与编者、用户与用户等的互动互补,从而在词典中构建多模态话语情景。
4) 词典信息不再是按词条完整呈现的平面文本结构,而是按关系(SQL)或非关系型数据库(NoSQL)结构组织和存储的多模态数据。同一词条的信息项(如注音、屈折变化、基本注释、释义、例证等)要被切分成相对独立但与词目词关联的数据元,分别与同一词典中其他词条的同类数据存储在相应的数据表格中,并自动进行特征标注。每一个数据化的词典信息项都被计算机赋予一个或若干个标记,以便为各类用户提供个性化的精准服务。
25. Martinec R. Topics in Multimodality. ∥Hasan R, Matthiessen C, Webster J.(eds.) Continuing Discourse on Language(Vol.1). London & Oakville:Equinox, 2005:157-181.
26. Matthiessen C.The Multimodal Page:A Systemic Functional Exploration.∥Royce T D, Bowcher W.(eds.) New Directions in the Analysis of Multimodal Discourse. New Jerse & London:Lawrence Erlbaum Associates, 2007:1-62.
27. New London Group. A Pedagogy of Multiliteracies:Designing Social Futures. Harvard Educational Review 1996(4):4-75.
28. Royce T. Intersemiotic Complementarity:A Framework for Multimodal Discourse Analysis.∥ Royce T, Bowcher W.(eds.) New Directions in the Analysis of Multimodal Discourse. New Jersey & London:Lawrence Erlbaum Associates, 2007:62-110.
29. Wierzbicka A. Semantics:Primes and Universals. Oxford:Oxford University Press, 1996:
258-270.
30. Williamson B. What Are Multimodality,Multisemiotics and Multi-Literacies:A Brief Guide to Some Jargon. NESTA Futurelab,2005.(Online. Accessed 23 Oct. 2015. http:∥www.Futurelab.org.uk/viewpoint/art49.htm.)
(廣东外语外贸大学文科基地/词典学研究中心 广州 510420)
(责任编辑 马 沙)
猜你喜欢 融媒体 融媒体时代全面深化电视新闻质量管理记者摇篮(2018年5期)2018-07-23融媒体时代的新闻叙事策略探究智富时代(2018年4期)2018-07-10融媒体时代的新闻叙事策略探究智富时代(2018年4期)2018-07-10融媒体时代高校电视台的定位与发展新教育时代·教师版(2018年12期)2018-05-24从用户需求角度谈广播可视化的操作路径中国广播(2017年12期)2018-03-01新媒体时代高校广告设计教学改革的趋势新闻爱好者(2017年12期)2018-01-10融媒体时代的故事传播中国广播(2017年11期)2017-12-02“融媒体”时代电视主持人面临的挑战及对策今传媒(2017年8期)2017-09-09融媒体时代中美广告传播策略的对比分析今传媒(2017年6期)2017-07-12融媒体时代下电视媒体传播新思路分析记者摇篮(2017年5期)2017-05-18